
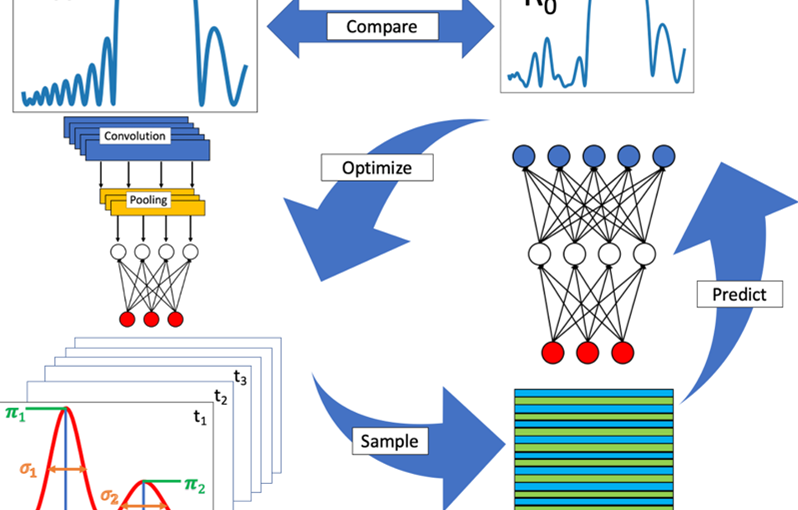
تجزیه و تحلیل داده های فیزیک ذرات
یک هدف متداول در تجزیه و تحلیل داده های فیزیک ذرات، برآورد یک پارامتر فیزیکی زیربنایی از داده های مشاهده شده است، در شرایطی که پارامتر به خودی خود قابل مشاهده نیست، اما مقدار آن توزیع قابل مشاهده ها را تغییر می دهد. یک رویکرد معمولی استفاده از تخمین حداکثر درستنمایی (MLE) برای استخراج مقادیر پارامترهای اساسی و عدم قطعیت های آماری آنها از توزیع های تجربی در داده های مشاهده شده است. به منظور انجام این کار، یک مدل آماری p(x|θθ) از مشاهده پذیر(ها)، به عنوان تابعی از پارامترهای اساسی، باید در دسترس باشد. اینها اغلب فقط از شبیه سازی مونت کارلو در دسترس هستند، نه از پیش بینی های تحلیلی. در استفاده معمولی، مقدار یک پارامتر در محدوده ای از مقادیر ممکن تغییر می کند. سپس مدلهای مشتقشده (که از هیستوگرامها یا سایر تخمینگرهای چگالی هسته تعیین میشوند، یا با توابع تحلیلی تقریبی شدهاند) با توزیعهای موجود در دادههای مشاهدهشده برای تخمین پارامتر مقایسه میشوند.
تعدادی از روش ها برای انجام این نوع استنتاج در ادبیات بحث شده است. برای مثال Refs را ببینید. [1،2،3،4،5،6]. برخی از اینها همچنین از رویکردهای یادگیری ماشینی استفاده می کنند و بسیاری از استفاده از مشاهده پذیرهای متعدد به منظور بهبود قدرت آماری پشتیبانی می کنند.

اگر یک مدل آماری کامل داشته باشیم p(x|θθ)
برای مشاهده پذیرهای موجود برای هر مقدار داده شده از پارامتر، MLE را می توان محاسبه کرد. متأسفانه، تعیین این امر معمولاً به صورت تحلیلی دشوار است، به خصوص اگر چندین قابل مشاهده با همبستگی، اثرات آشکارساز یا سایر عوارض وجود داشته باشد. یک روش جایگزین، تقریب مستقیم تابع احتمال پارامتر، L(θθ|x) است.


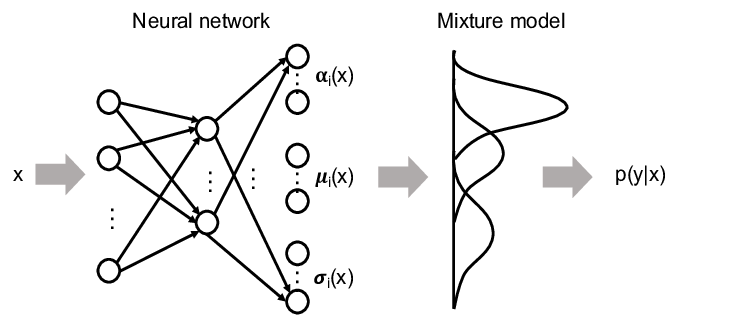
شبکههای چگالی مخلوط [7] یک کار مرتبط را حل میکنند. آنها برای تقریب تابع چگالی خلفی p(θθ|x) استفاده می شوند.
پارامترهای θθ از ویژگی های ورودی x به عنوان مجموع توابع چگالی احتمال پایه (PDFs). به طور خاص، شبکه عصبی ضرایب/پارامترهای چگالی خلفی را پیشبینی میکند. با قضیه بیز، چگالی خلفی را که توسط شبکه خروجی می شود، به تابع درستنمایی پارامتر مورد نظر مرتبط می کنیم. قابل ذکر است، به دلیل انعطافپذیری ساختار شبکه، MDNها امکان استفاده مستقیم از مشاهدهپذیرهای چند بعدی و همچنین تقریب تابع چگالی خلفی را با هر مجموعه دلخواه از فایلهای PDF پایه را میدهند.
هنگام آموزش MDN ها، معمولاً فرض می شود که همه مقادیر پارامتر ورودی به یک اندازه در مجموعه داده آموزشی نمونه برداری می شوند و این پارامتر پیوسته است. در اصل، این معادل تعیین یک قبل مسطح برای کاربرد قضیه بیز است که چگالی خلفی را که MDN یاد میگیرد به تابع درستنمایی ترجمه میکند.


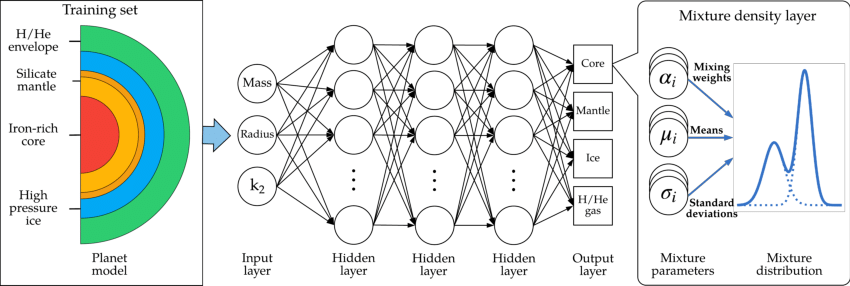
با این حال، این مجموعه دادهها ممکن است به دلایل مختلف به آسانی در دسترس نباشند: ممکن است نمونههای مونت کارلو را با تجزیه و تحلیل با استفاده از تکنیکهای تخمین دیگر که از هیستوگرامها در مقادیر پارامترهای خاص برای ایجاد الگوها استفاده میکنند، به اشتراک بگذارند، یا ممکن است مشکلات محاسباتی با تغییر مقادیر پارامتر در الگو وجود داشته باشد. ژنراتور مونت کارلو برای هر رویداد. برای مثال، در اندازهگیری جرم کوارک بالا، مولدهای رویداد مونت کارلو به طور کارآمدی از شبیهسازی رویدادها در امتداد زنجیرهای از مقادیر بالای جرم ممکن پشتیبانی نمیکنند. در عوض، رویدادها در جایی ایجاد میشوند که جرم بالایی روی یک مقدار در شبکهای از مقادیر پارامتر ممکن تنظیم شده باشد. در این کار، ما مسائلی را مورد بحث قرار میدهیم که هنگام استفاده از نمونههای آموزشی با مقادیر پارامترهای گسسته، به جای توزیع پارامترهای پیوسته، برای تخمین پارامترها با MDNها به وجود میآیند.
یک موضوع مرتبط زمانی به وجود می آید که از محدوده محدودی از مقادیر پارامتر در آموزش استفاده می شود، که در آن شبکه آموزش دیده به دلیل فقدان نسبی رویدادهای آموزشی در آن مجاورت، تمایلی به پیش بینی مقادیر نزدیک به مرزهای محدوده ندارد. این امر حتی زمانی رخ میدهد که آموزش با توزیع پارامتر پیوسته انجام میشود و بر کارهایی غیر از تخمین احتمال، مانند رگرسیون ساده تأثیر میگذارد.
شبکههای چگالی مخلوط به عنوان تقریبکننده احتمال
شبکه تراکم مخلوط یک شبکه عصبی است که در آن خروجی مجموعهای از پارامترهای یک تابع است که بهعنوان یک PDF بهطور مناسب نرمالسازی شده تعریف میشود. خروجی های MDN می تواند به عنوان مثال، میانگین، عرض و سهم نسبی تعداد (ثابت) توزیع های گاوسی باشد. اما، به طور کلی، هدف استفاده از MDN به دست آوردن تخمینی از تابع چگالی خلفی p(θθ|x) است.
یک مجموعه داده که شامل پارامترهای θθ و مشاهدات x است.
MDN چگالی خلفی هدف را با مجموع وزنی n توابع PDF پایه عمومی Bn نشان می دهد،
p~(θθ|x;Z)=∑i=1nci(x)⋅Bi(θθ;zi(x))، (1)
که در آن ci(x) و zi(x) ضرایب وابسته به x و پارامترهای توابع پایه هستند که توسط شبکه پیشبینی میشوند، و Z={ci}∪{zi} برای نشان دادن همه ضرایب مدل آموخته شده به طور معمول، شرایط ci∈[0,1] و ∑ici=1، برای مثال از طریق تابع softmax اعمال می شوند. در اصل، توابع پایه می توانند هر مجموعه ای از پی دی اف های پایه باشند. یک انتخاب مفید برای بسیاری از کاربردها، ترکیبی از n توابع گاوسی است. (از آنجایی که ما یک تابع چگالی خلفی یک پارامتر پیوسته را تخمین می زنیم، ممکن است انتظار یک حداقل را در لگاریتم منفی این تابع داشته باشیم. حداقل می تواند درجه دوم به ترتیب پیشرو باشد، و گاوسیان را به یک انتخاب طبیعی برای توابع پایه PDF تبدیل می کند.) برای آن انتخاب. ، خروجی شبکه عصبی مجموعه ای از 3n-1 ضرایب مستقل Z(x)={ci(x)،μi(x)،σi(x)} است (با یک شرط نرمال سازی softmax).
برای آموزش شبکه، در هر دوره، تابع خروجی شبکه p~(θθ|x;Z) برای هر نقطه در مجموعه داده های آموزشی {(θθj,xj)} ارزیابی می شود. تابع هزینه،
C(Z)=−log[∏j=0mp~(θθj|xj;Z(xj))]، (2)
لگاریتم منفی حاصل ضرب این مقادیر است. خطا به روش استاندارد از طریق شبکه منتشر می شود و هزینه برای تعیین ضرایب ایده آل به حداقل می رسد.
Z^Z^=argmaxZ{C(Z)}. (3)
از نقطه نظر فیزیک تخمین پارامتر با دادههای گسسته، ما در واقع علاقهای به استفاده از شبکه برای مدلسازی چگالی خلفی واقعی نداریم، همانطور که معمولاً در برنامههای MDN ممکن است انجام شود. (با نمونههای آموزشی گسسته، عقب واقعی مجموعه دادههای آموزشی شامل توابع دلتا در مقادیر مختلف θθ است که در آن هر الگو قرار دارد.) در عوض، p~(θθ|x;Z^) ایجاد شده توسط MDN را به یک تخمین تبدیل میکنیم. تابع درستنمایی L(θθ|x). با استفاده از قضیه بیز،
L(θθ|x)=p~(x|θθ;Z^)=p~(θθ|x;Z^)p(x)p(θθ). (4)
به طور قابل توجهی، در طرز فکر تخمین برخی پارامترها θθ، تا زمانی که ما از یک p (θθ) قبلی مطمئن شویم، احتمال اینکه به دنبال آن هستیم و چگالی پسینی که توسط MDN آموزشدیده خروجی میشود تنها با یک عامل ضربی نامربوط – p قبلی متفاوت است. (x)، که توسط کل مجموعه آموزشی تعیین می شود، و به θθ بستگی ندارد.
برای اینکه MDN به طور موثر درون یابی شود، مهم است که آزادی بیش از حد در خروجی MDN وجود نداشته باشد. برای مثال، فرض کنید تعداد مساوی الگوهای آموزشی و مولفه های گاوسی در p~(θθ|x) وجود داشته باشد. سپس شبکه میتواند اساساً توابع گاوسی را به توابع دلتا در هر مقدار θθ قالب فرو بپاشد و تابع هزینه را بدون محدودیت کاهش دهد. تا زمانی که مقادیر مشاهدهشده x را میتوان بهطور منطقی با مقادیر چندگانه θθ تولید کرد، و تعداد توابع پایه در MDN به طور معقولی کم نگه داشته شود، MDN به طور طبیعی مجبور میشود بین نقاط پارامتر درونیابی کند، همانطور که برای تخمین L(θθ است. |x).
منابع
- J. Brehmer, K. Cranmer, G. Louppe, J. Pavez, Phys. Rev. D 98(5), 052004 (2018). https://doi.org/10.1103/PhysRevD.98.052004Article ADS Google Scholar
- F. Flesher, K. Fraser, C. Hutchison, B. Ostdiek, M.D. Schwartz, Parameter inference from event ensembles and the top-quark mass (2020)
- A. Andreassen, S.C. Hsu, B. Nachman, N. Suaysom, A. Suresh, Phys. Rev. D 103(3), 036001 (2021). https://doi.org/10.1103/PhysRevD.103.036001Article ADS Google Scholar
- M. Baak, S. Gadatsch, R. Harrington, W. Verkerke, Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 771, 39–48 (2015). https://doi.org/10.1016/j.nima.2014.10.033Article ADS Google Scholar
- K. Cranmer, G. Lewis, L. Moneta, A. Shibata, W. Verkerke, HistFactory: a tool for creating statistical models for use with RooFit and RooStats. Technical Report. CERN-OPEN-2012-016, New York University, New York (2012). https://cds.cern.ch/record/1456844
- A.L. Read, Nucl. Instrum. Methods A 425, 357 (1999). https://doi.org/10.1016/S0168-9002(98)01347-3Article ADS Google Scholar
- C.M. Bishop, Mixture density networks. Aston University Neural Computing Research Group Report NCRG/94/004 (1994)
برای دانلود پروژه نمونه شبکه های تراکم مخلوط (MDN) برای تخمین توزیع و عدم قطعیت به همراه شبیه سازی، لطفا اینجا کلیک کنید.
پروژه مشابه دارید؟
برای ثبت سفارش در سیمیا می توانید از طریق اپلیکیشن سیمیا، یا فرم ثبت سفارش در سایت اقدام کرده و یا از طریق ایمیل، واتساپ، تلگرام و اینستاگرام اقدام نمایید.
اپلیکیشن سیمیا را از بازار و مایکت دانلود کنید.
سریع ترین راه پاسخگویی سیمیا، واتساپ و سروش می باشد. لینک واتساپ، اینستاگرام و تلگرام در پایین سایت وجود دارد.
09392265610
نشانی ایمیل سیمیا simiya_ht@yahoo.com می باشد.
از برقراری تماس برای هماهنگی پروژه خودداری کنید، حجم بالای سفارشات به ما اجازه نمی دهد تا از طریق تلفن پاسخگوی شما عزیزان باشیم، حتما درخواست خود را به صورت مکتوب و از طریق یکی از راه های ذکر شده فوق ارسال نمایید، درخواست خود را به طور کامل و با تمام فایل ها و توضیحات لازم ارسال نمایید تا مدت زمان بررسی آن به حداقل برسد. پس از تعیین کارشناس، در اسرع وقت به شما پاسخ می دهیم.
