ایجاد آرشیو یا مخازن بزرگ با در دسترس بودن داده های باز و ابزارهای مدیریت آنها آسان تر می شود. گاهی اوقات ادغام داده های مختلف در یک مخزن می تواند مفید باشد. محتوای متنی باید با برچسب های معنایی غنی شود، یا توسط فهرست نویس ها ارائه می شود یا به طور خودکار استخراج می شود تا به طور موثر قابل استفاده باشد. برای دستیابی به استفاده کارآمد و مؤثر از این حاشیه نویسی ها (در این مقاله، برچسب ها، کلمات کلیدی و حاشیه نویسی متنی به عنوان مترادف در نظر گرفته شده اند و بنابراین به جای یکدیگر استفاده می شوند) در بازیابی اطلاعات، تجزیه و تحلیل احساسات، یا سیستم های توصیه، باید به اندازه کافی کلی باشند که بسیاری از آنها را نشان دهند. موارد، اما نه خیلی زیاد. آنها باید به اندازه کافی خاص باشند تا برخی موارد را نشان دهند، اما نه خیلی کم. روشها، مدلها و ابزارهایی برای تمیز کردن، هماهنگسازی و دستهبندی آنها و به عبارتی استفاده بهینه از آنها مورد نیاز است. بنابراین، چالش واقعی که باید با آن روبرو شد، مربوط به کیفیت داده ها و رضایت کاربران از توانایی پاسخگویی به نیاز آنها به اطلاعات است.
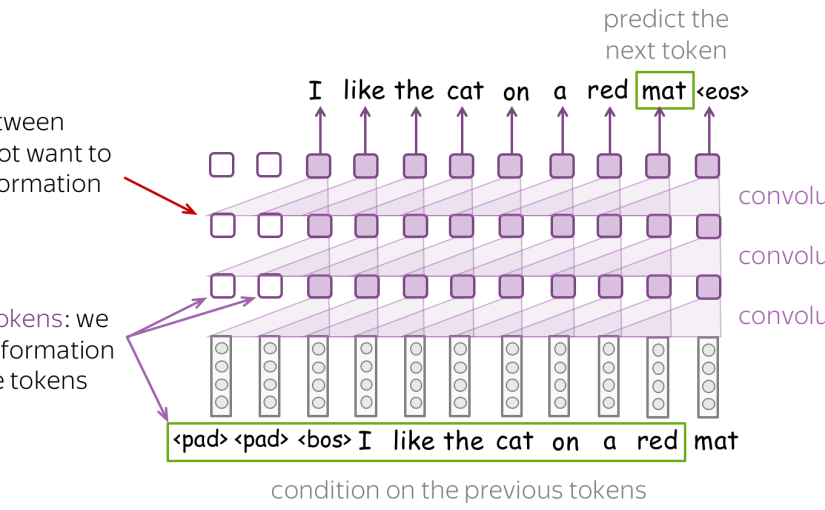
شناسایی خودکار زبان موضوعی است که در طول سالها در زمینههای مختلف مانند ترجمه ماشینی، سنتز گفتار و بازیابی اطلاعات مورد توجه بسیاری قرار گرفته است. در خط لوله پردازش متن، شناسایی زبان یکی از اولین فعالیت ها است. به عنوان مثال، به Google Translate (https://translate.google.com/ دسترسی به 30 ژانویه 2022) یا DeepL (https://www.deepl.com/translator در 30 ژانویه 2022) فکر کنید که این امکان را به شما ارائه می دهد. به طور خودکار زبان متنی که باید ترجمه شود را تشخیص دهد. یک نظرسنجی در سال 2019 [1] نمای کلی بسیار گسترده ای از ویژگی ها، روش ها و مدل های مختلف مورد استفاده در ادبیات برای شناسایی زبان، در حوزه های مختلف ارائه می دهد. به گفته نویسندگان، تحت شرایط کنترل شده، مانند محدود کردن تعداد زبان ها به مجموعه کوچکی از زبان های اروپای غربی و استفاده از متن های طولانی، دستوری و ساختار یافته مانند اسناد دولتی به عنوان داده های آموزشی، می توان به دقت تقریباً کامل دست یافت. هنگام برخورد با متون بسیار کوتاه، با اشتباهات املایی یا زبان مختلط، مشکل همچنان پیچیده است.
با توجه به تشخیص خودکار خطا، انواع مقالات مرتبط با جنبه های خاص مشکل را می توان در ادبیات پیدا کرد. مرجع. [2] به مشکل خاص پرونده پزشکی در زبان فارسی می پردازد که می تواند خطاهای غیرکلمه ای را شناسایی کند. در [3]، نویسندگان به زبان تایلندی می پردازند و با مشکل رسیدگی به کلماتی که در فرهنگ لغت وجود ندارند، مواجه می شوند. استفاده از مدل های جاسازی کلمه، مانند word2vec، GloVe یا Bert، همراه با فاصله ویرایش، راه حلی است که توسط [4] اتخاذ شده است، که در آن مدل های از پیش آموزش دیده پتانسیل خود را در کار تصحیح غلط املایی ثابت کردند. ادبیات در مورد مشکل شناسایی متون توهین آمیز بسیار گسترده است. در سال 2019، یکی از وظایف SemEval استفاده از یادگیری ماشینی گروهی برای تشخیص سخنان مشوق نفرت بود [5]: این مقاله بر ضرورت داشتن نمونه های آموزشی بیشتر، از مثبت تر تا منفی تر، تاکید کرد. مدلهای سادهتر دارای ویژگیهای قابل درک هستند، در حالی که مدلهای پیچیده نتایج بهتری به دست میآورند.
شبکه های عصبی مصنوعی با موفقیت در درک متن به کار گرفته شده اند. در [6]، گلدبرگ مدلهای شبکههای عصبی را از منظر تحقیق پردازش زبان طبیعی بررسی میکند، تا محققان زبان طبیعی را با تکنیکهای عصبی بهروز کند. روش های شبکه عصبی مختلف برای شناسایی خودکار زبان پیشنهاد شده است [7،8،9]. این مقالات موافق هستند که متون کوتاه بر کیفیت نتایج و همچنین اندازه مجموعه داده های آموزشی تأثیر می گذارد.
در [10]، نویسندگان مروری سیستماتیک از رویکردهای توسعه یافته تاکنون ارائه می دهند. برای توضیح زمینه، معماری LSTM [11] و sequence2sequence [12] برای تصحیح خودکار خطا استفاده شد. فقدان منابع برای زبان های خاص مستلزم توجه ویژه است، همانطور که در [13]، برای زبان های هندی. مرجع. [14] از مدلهای ترتیب به دنباله (seq2seq) برای تصحیح املا در زبان ترکی، بر روی مجموعه دادههای غلط املایی بهطور مصنوعی ایجاد شده استفاده میکند.

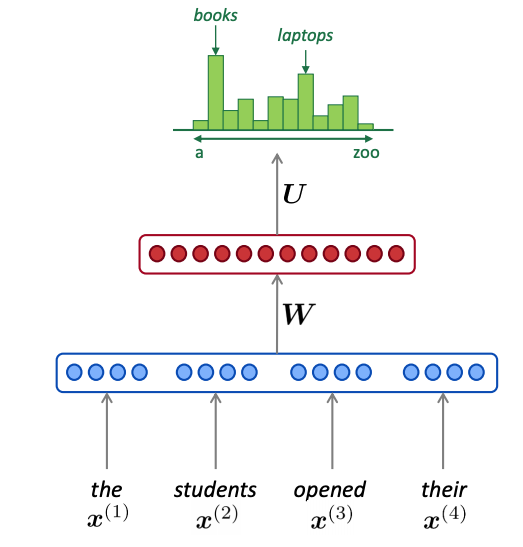
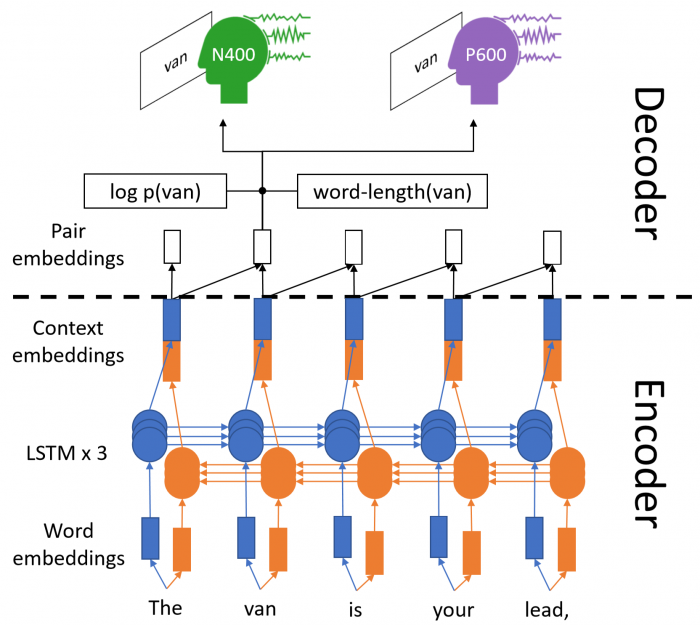
در [15]، نویسندگان یک چارچوب کلی از معیارهای تشابه نحوی برای تطبیق متن کوتاه معرفی می کنند. مدل های جاسازی کلمه مانند word2vec [16،17] یا BERT [18] مدیریت متن را تا حد زیادی بهبود بخشیده اند. نویسندگان [19] یک رویکرد مبتنی بر یادگیری را برای ساخت خودکار واژه نامه دامنه از کد منبع و مستندات نرم افزار، با استفاده از مدل های جاسازی کلمه ادغام شده با شباهت واژگانی پیشنهاد کردند. ادغام مدلهای جاسازی کلمه با الگوریتمهای خوشهبندی در حال حاضر توسط گروههای تحقیقاتی مختلف، عمدتاً با اهداف طبقهبندی و/یا در زمینههای خاص (مثلا [20،21])، به دلیل توانایی آن در استخراج کلمات کلیدی معنایی و تمایز، مورد مطالعه قرار میگیرد.


منابع
- Jauhiainen, T.L. Automatic language identification in texts: A survey. J. Artif. Intell. Res. 2019, 65, 675–782. [Google Scholar] [CrossRef][Green Version]
- Yazdani, A.; Ghazisaeedi, M.; Ahmadinejad, N.; Giti, M.; Amjadi, H.; Nahvijou, A. Automated misspelling detection and correction in persian clinical text. J. Digit. Imaging 2020, 33, 555–562. [Google Scholar] [CrossRef] [PubMed]
- Somboonsak, P. Misspelling error detection in Thai language application. In Proceedings of the 6th International Conference on Information Technology: IoT and Smart City, New York, NY, USA, 31 December 2018; pp. 19–24. [Google Scholar]
- Hu, Y.; Jing, X.; Ko, Y.; Rayz, J.T. Misspelling Correction with Pre-trained Contextual Language Model. In Proceedings of the 2020 IEEE 19th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Beijing, China, 26–28 September 2020; pp. 144–149. [Google Scholar]
- Ramakrishnan, M.; Zadrozny, W.; Tabari, N. UVA Wahoos at SemEval-2019 Task 6: Hate Speech Identification using Ensemble Machine Learning. In Proceedings of the 13th International Workshop on Semantic Evaluation; Association for Computational Linguistics, Nanchang, China, 27–29 September 2019; pp. 806–811. [Google Scholar]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef][Green Version]
- Simões, A.A. Language Identification: A Neural Network Approach. In Proceedings of the 3rd Symposium on Languages, Applications and Technologies, Bragança, Portugal, 19–20 June 2014. [Google Scholar]
- Botha, G.R. Factors that affect the accuracy of text-based language identification. Comput. Speech Lang. 2012, 26, 307–320. [Google Scholar] [CrossRef][Green Version]
- Lopez-Moreno, I.G.-D.-R. Automatic language identification using deep neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 5337–5341. [Google Scholar]
- Hládek, D.J. Survey of Automatic Spelling Correction. Electronics 2020, 9, 1670. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Etoori, P.M. Automatic spelling correction for resource-scarce languages using deep learning. In Proceedings of the ACL 2018, Student Research Workshop, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Büyük, O. Context-Dependent Sequence-to-Sequence Turkish Spelling Correction. ACM Trans. Asian Low-Resour. Lang. Inf. Processing (TALLIP) 2020, 19, 1–16. [Google Scholar] [CrossRef]
- Gali, N.; Mariescu-Istodor, R.; Hostettler, D.; Fränti, P. Framework for syntactic string similarity measures. Expert Syst. Appl. 2019, 129, 169–185. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J.; Sutskever, L.; Zweig, G. Tool for Compu-Ting Continuous Distributed Representations of Words: Word2vec. Available online: https://code.google.com/p/word2vec (accessed on 30 January 2022).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Processing Syst. 2013, 26, 3111–3119. [Google Scholar]
- Devlin, J.M.-W. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, C.; Peng, X.; Liu, M.; Xing, Z.; Bai, X.; Xie, B.; Wang, T. A learning-based approach for automatic construction of domain glossary from source code and documentation. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 12 August 2019; pp. 97–108. [Google Scholar]
- Comito, C.; Forestiero, A.; Pizzuti, C. Word Embedding based Clustering to Detect Topics in Social Media. In Proceedings of the 2019 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Thessaloniki, Greece, 14–17 October 2019. [Google Scholar]
- Hu, J.; Li, S.; Yao, Y.; Yang, G.; Hu, J. Patent keyword extraction algorithm based on distributed representation for patent classification. Entropy 2018, 20, 104. [Google Scholar] [CrossRef] [PubMed][Green Version]
برای دانلود پروژه نمونه مدل سازی زبان با استفاده از یادگیری عمیق به همراه شبیه سازی، اینجا کلیک کنید.


پروژه مشابه دارید؟
برای ثبت سفارش در سیمیا می توانید از طریق اپلیکیشن سیمیا، یا فرم ثبت سفارش در سایت اقدام کرده و یا از طریق ایمیل، واتساپ، تلگرام و اینستاگرام اقدام نمایید.
اپلیکیشن سیمیا را از بازار و مایکت دانلود کنید.
سریع ترین راه پاسخگویی سیمیا، واتساپ و سروش می باشد. لینک واتساپ، اینستاگرام و تلگرام در پایین سایت وجود دارد.
09392265610
نشانی ایمیل سیمیا simiya_ht@yahoo.com می باشد.
از برقراری تماس برای هماهنگی پروژه خودداری کنید، حجم بالای سفارشات به ما اجازه نمی دهد تا از طریق تلفن پاسخگوی شما عزیزان باشیم، حتما درخواست خود را به صورت مکتوب و از طریق یکی از راه های ذکر شده فوق ارسال نمایید، درخواست خود را به طور کامل و با تمام فایل ها و توضیحات لازم ارسال نمایید تا مدت زمان بررسی آن به حداقل برسد. پس از تعیین کارشناس، در اسرع وقت به شما پاسخ می دهیم.