مدل های مولد یادگیری عمیق
مدلهای یادگیری عمیق مستقیماً ویژگیهای سطح بالای دادههای بدون ساختار را یاد میگیرند [1]. قدرت واقعی یادگیری عمیق در توانایی آن در مدیریت داده های بدون ساختار نهفته است. به خصوص، مدل سازی مولد داده های بدون ساختار مانند تصاویر یا متن جدید را تولید می کند. بنابراین، یادگیری عمیق تأثیر زیادی در زمینه مدلهای مولد دارد.
مدل سازی تولیدی مرز بعدی یادگیری ماشین است. یادگیری عمیق تنها چند سال است که در مدل سازی مولد به کار گرفته شده است. در کنفرانس NIPS (سیستمهای پردازش اطلاعات عصبی) 2014، ایان گودفلو از Google Brain GAN (شبکههای متخاصم مولد) را معرفی کرد [2]. GAN تعدادی الگوریتم را ایجاد کرده است و این زمینه را بیشتر پیش برده است.
از اواسط سال 2018، پیشرفت های زیادی در زمینه مدل سازی توالی و مدل سازی مولد مبتنی بر تصویر حاصل شده است. مدلسازی توالی عمدتاً توسط ترانسفورماتور [3] هدایت میشد، یک ماژول مبتنی بر توجه که شبکههای عصبی گردشی یا کانولوشن را حذف میکند. به عنوان مثال میتوان به BERT گوگل (نمایش رمزگذار دوطرفه از ترانسفورماتور)، GPT-3 (ترانسفورماتور پیشآموزششده-3) برای مدلسازی زبان، WaveGAN موازی برای سنتز گفتار و MuseNet برای ترکیب موسیقی [4،5،6،7] اشاره کرد. فناوریهای مبتنی بر GAN مانند PGGAN (رشد پیشرونده شبکههای متخاصم مولد)، SAGAN (شبکههای متخاصم مولد خود توجه)، BigGAN و StyleGAN توسعه یافتهاند. بنابراین موقعیت تولید تصویر بهبود می یابد [8،9،10،11].
اخیراً علاقه رسانه ها به پروژه های مدل سازی مولد افزایش یافته است. StyleGAN معرفی شده توسط NVIDIA یک تصویر واقعی از چهره ایجاد می کند. GPT-3 از هوش مصنوعی باز یک جمله کامل را با ارائه یک دستور مقدمه کوتاه ایجاد می کند. از سال 2021، GAN و روشهای مبتنی بر توجه به طور قابل توجهی تکامل یافتهاند و ویدیو، متن، گفتار و موسیقی تولید میکنند که حتی متخصصان نیز نمیتوانند آنها را تشخیص دهند.
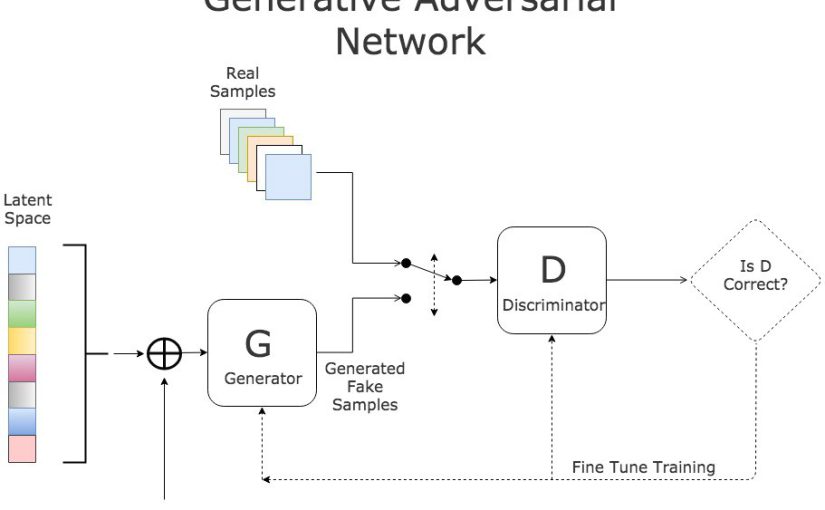
GAN دو شبکه دارد: مولد و تفکیک کننده. ژنراتور نویز تصادفی را به یک نمونه واقعی تبدیل می کند، در حالی که تشخیص دهنده تشخیص می دهد که نمونه ورودی واقعی است یا سنتز شده توسط ژنراتور. نمونه ای از ورودی-خروجی برای هر دو شبکه در شکل 1 نشان داده شده است.
ابتدا یک نمونه واقعی از مجموعه آموزشی برای تصادفی انتخاب می شود. سپس خروجی ژنراتور در یک مجموعه آموزشی ترکیب می شود و تفکیک کننده آموزش می بیند. هدف تصویر واقعی “1” و هدف تصویر تولید شده “0” است. تصویر واقعی مقداری نزدیک به “1” و تصویر مصنوعی، مقداری نزدیک به “0” تولید می کند.
آموزش ژنراتور دشوار است زیرا تصویر واقعی به هیچ نقطه ای از فضای پنهان نگاشت نمی شود. وقتی خروجی مولد به ممیز وارد می شود، احتمال واقعی بودن خروجی داده می شود. چنین احتمالی خروجی GAN است. ورودی یک بردار فضای پنهان d بعدی است که به طور تصادفی ایجاد می شود و خروجی “1” برای آموزش GAN با تولید یک دسته آموزشی است. خروجی باید روی “1” تنظیم شود تا یک نمونه واقعی تولید شود.
تابع تلفات آنتروپی متقاطع باینری بین خروجی تفکیک کننده و هدف “1” است. هدف یک مقدار باینری است و از یک واحد خروجی با تابع فعالسازی سیگموئید استفاده میکند [12]. هنگام آموزش GAN، وزن تفکیک کننده باید انجماد باشد تا فقط وزن ژنراتور به روز شود. در غیر این صورت، طوری تنظیم می شود که تصویر تولید شده را واقعی در نظر بگیرد.

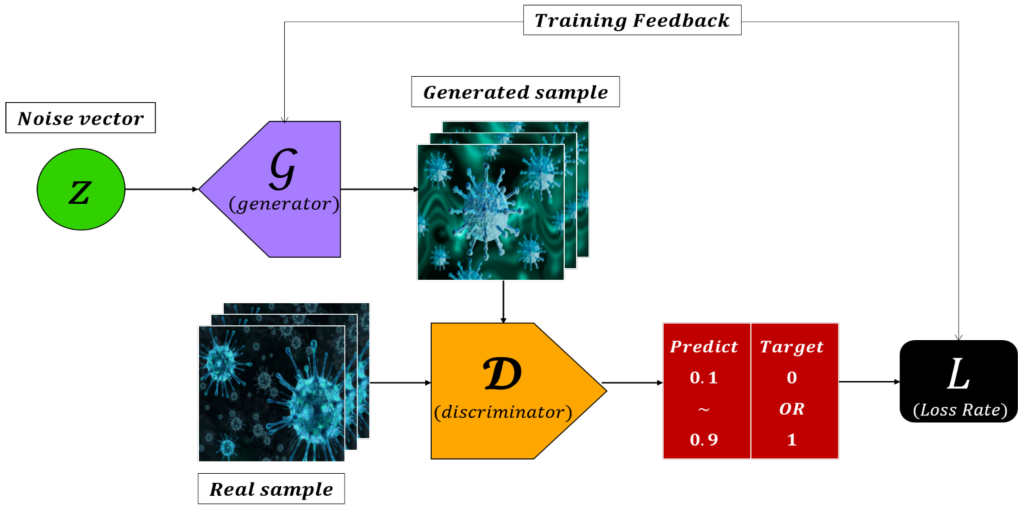
مدل تولیدی می تواند تصاویر را با درک و یادگیری توزیع آماری داده های آموزشی ترکیب کند. در هر صورت، وزن شبکه از طریق پس انتشار [13] آموخته می شود. ادبیات GAN با بردارهای چند بعدی سر و کار دارد و بردارها را در فضای احتمال مورب می کند. بردارهای پنهان معمولاً با z نشان داده می شوند. در زمینه پردازش سیگنال، بردارها با نمادهای کوچک نشان داده می شوند تا بر ماهیت چند بعدی متغیرها تأکید شود. بنابراین، pdata(x) تابع چگالی احتمال برای بردار تصادفی x از R|x| است. احتمال اینکه یک متغیر تصادفی پیوسته در یک بازه معین گنجانده شود، چگالی احتمال نامیده می شود و این به عنوان تابع چگالی احتمال بیان می شود. pG(x) توزیع بردارهای تولید شده در G را نشان می دهد. θD و θG به ترتیب وزن هایی هستند که از G و D آموخته می شوند.
مانند همه الگوریتم های یادگیری عمیق، آموزش نیز به یک تابع هدف نیاز دارد. در این زمان، تابع ضرر، تابع هدف و تابع هزینه یکسان هستند. به طور دقیق، تابع هزینه مجموع توابع ضرر را برای تمام داده های آموزشی نشان می دهد و تابع هدف تابع هدف برای بهینه سازی به طور کلی تر است. با این حال، به طور کلی، این سه اصطلاح اغلب به جای یکدیگر استفاده می شوند. هنگامی که دو تابع هدف به طور مداوم به روز می شوند، توابع هدف G و D با JG(θG;θD) و JD(θD;θG) نشان داده می شوند تا یادآوری کنند که مجموعه پارامترهای θG و θD به یکدیگر وابسته هستند.
هنگامی که گرادیان چند بعدی به روز می شود، عملگر گرادیان وزن G به صورت ∇θG و وزن D به صورت ∇θD بیان می شود. ∇ یک عملگر دیفرانسیل است که در آن هر جزء به عنوان یک بردار رسمی با توجه به مختصات دکارتی x,y,z نمایش داده می شود. در مورد گرادیان Expected، با E∇ نشان داده می شود.


توزیع داده ها
مسئله اصلی در پردازش سیگنال و آمار، تخمین چگالی است که نمایش داده های پارامتریک یا ناپارامتریک را به دست می آورد. توزیع تولید داده برای نشان دادن چگالی احتمال اولیه یا تابع جرم احتمال داده های مشاهده شده استفاده می شود. GAN شباهت بین توزیع مدل کاندید و توزیع داده واقعی را محاسبه کرده و یاد می گیرد.
قضیه بیز می تواند تمام مسائل استنتاج در بینایی کامپیوتر را از طریق توابع چگالی احتمال شرطی حل کند [14]. می توان از آن به عنوان مدلی برای یادگیری توزیع مفاصل مورد نظر و داده های مشاهده استفاده کرد. مشکل این است که ساخت یک تابع احتمال برای تصاویر واقعی با ابعاد بالا دشوار است. GAN به صراحت روشی برای ارزیابی توابع چگالی ارائه نمی دهد و G به طور ضمنی توزیع داده های واقعی را ضبط می کند.
مدل های GAN
تابع هدف
تابع هدف بسیار مهم است زیرا با چالش های GAN مرتبط است. اگر از یک تابع هدف استفاده می کنید که برای کاری که می خواهید حل کنید مناسب نیست، GAN می تواند در طول آموزش از کنترل خارج شود. یک مثال معمولی زمانی است که تلفات به ارتعاش در می آیند. از دست دادن تفکیک کننده و ژنراتور برای مدت طولانی حالت پایداری را نشان نمی دهد و به شدت ارتعاش می کند.
به عنوان مثالی دیگر، اگرچه کیفیت تصویر با گذشت زمان بهبود مییابد، عملکرد تلفات ژنراتور ممکن است افزایش یابد. این به دلیل عدم ارتباط بین از دست دادن ژنراتور و کیفیت تصویر است. عدم ارتباط، مشاهده روند آموزش GAN را دشوار می کند. توابع هدف معرفی شده در این مقاله روش های مناسبی برای آموزش GAN های پیچیده در نظر گرفته می شوند.


WGAN (شبکه های متخاصم مولد Wasserstein)
اتلاف WGAN از این جهت قابل توجه است که همگرایی ژنراتور و کیفیت نمونه را به هم مرتبط می کند. WGAN Wasserstein Loss را معرفی کرد که کیفیت نمونه ها را با همگرایی ژنراتور مرتبط می کند [15]. از دست دادن Wasserstein باعث بهبود پایداری در طول فرآیند بهینهسازی شد. ابتدا آریووسکی از yi=1 و yi=−1 استفاده کرد
به جای yi=1، yi=0 برای از دست دادن آنتروپی متقاطع باینری. علاوه بر این، تابع فعال سازی سیگموئید از آخرین لایه تشخیصگر حذف شد. بنابراین، پیشبینی پی به محدوده [0،1] محدود نمیشود، بلکه میتواند هر عددی در محدوده [−∞،∞] باشد. به همین دلیل، متمایز کننده WGAN را منتقد می نامند. تابع از دست دادن Wasserstein توسط رابطه (1) به دست می آید.
−1n∑ni=1(yipi) (1)
WGAN پیشبینی pi=D(xi)) و هدف yi=−1 را برای تصویر واقعی مقایسه میکند تا منتقد D را آموزش دهد. از دست دادن تابع تلفات منتقد WGAN را می توان با معادله (2) به حداقل رساند.
minD−(Ex~pX[D(x)]-Ez~pz[D(G(z))]) (2)
منتقد WGAN با افزایش امتیاز تصویر واقعی، تفاوت بین پیشبینی تصویر واقعی و تصویر تولید شده را به حداکثر میرساند. آموزش مولد WGAN مستلزم مقایسه پیش بینی و هدف برای تصویر تولید شده و محاسبه تلفات است. تابع تلفات مولد WGAN را می توان با معادله (3) به حداقل رساند.
minG−(Ez~pZ[D(G(z))]) (3)
تابع از دست دادن Wasserstein با آموزش تفکیک کننده همگرا می شود تا مولد به درستی به روز شود. این با GAN اولیه متفاوت است، جایی که مهم است اطمینان حاصل شود که تمایزکننده خیلی قوی نمی شود. از دست دادن Wasserstein می تواند تمرین تمایز و مولد را متعادل کند. WGAN چندین بار در طول به روز رسانی ژنراتور تمایز کننده را آموزش می دهد تا همگرا شود. به طور کلی، هنگام به روز رسانی یک ژنراتور یک بار، تشخیص دهنده پنج بار به روز می شود.
از آنجایی که WGAN وزن منتقدان را کاهش داده است، سرعت یادگیری تا حد زیادی کاهش می یابد. اگر گرادیان صحیح نباشد، ژنراتور نمی تواند جهت به روز رسانی وزن را یاد بگیرد. به همین دلیل، روش دیگری برای محدودیت لیپچیتز، WGAN-GP (Gradient Penalty) ارائه شد [16].
WGAN-GP (پنالتی Wasserstein GAN-Gradient)
WGAN-GP مشکلاتی مانند فروپاشی حالت و آموزش ناپایدار را حل می کند و آموزش GAN را قابل پیش بینی و قابل اعتماد می کند. WGAN-GP یک عبارت جریمه گرادیان را در تابع ضرر بحرانی گنجاند [17]. وزن منتقدان بریده نشده است. علاوه بر این، لایه عادی سازی دسته ای نباید برای منتقدان استفاده شود. نرمال سازی دسته ای یک همبستگی بین تصاویر در همان دسته ایجاد می کند، بنابراین از دست دادن جریمه گرادیان تأثیر کمتری دارد [18]. WGAN-GP راه دیگری را برای اعمال محدودیت لیپچیتز بر منتقدان پیشنهاد میکند: افزودن عبارتی به تابع ضرر که وقتی هنجار گرادیان منتقد به طور قابلتوجهی از «1» منحرف شود، جریمه میکند. در نتیجه، روند آموزش تا حد زیادی تثبیت شد.
از دست دادن جریمه گرادیان اختلاف مجذور بین هنجار گرادیان خروجی و یک است. این مدل به طور طبیعی وزن هایی را پیدا می کند که عبارت جریمه گرادیان را به حداقل می رساند. به عبارت دیگر، مدل برای پیروی از محدودیت لیپچیتز ساخته شده است. محاسبه گرادیان در همه جا در طول فرآیند آموزش دشوار است. WGAN-GP فقط در نقطه ای گرادیان را محاسبه می کند. برای اینکه از یک طرف سوگیری نداشته باشیم، جفت تصویر مصنوعی-تصویر واقعی همانطور که در شکل 2 نشان داده شده است به هم متصل می شوند و تصاویر درون یابی شده با استفاده از نقاط انتخاب شده تصادفی در امتداد یک خط مستقیم استفاده می شوند.
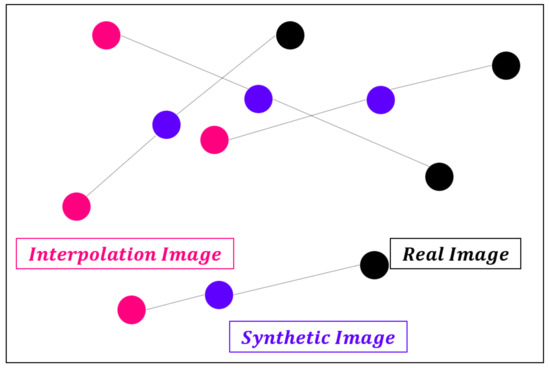
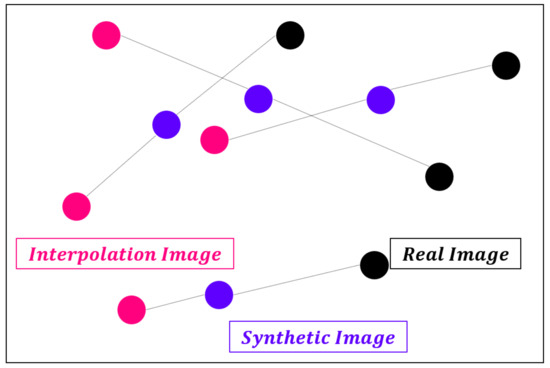
شکل 2. درون یابی بین تصاویر.
منابع
- Yann, L.; Yoshua, B.; Geoffrey, H. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. arXiv 2020, arXiv:1406.2661. Available online: https://arxiv.org/abs/1406.2661 (accessed on 21 April 2020).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. arXiv 2020, arXiv:1706.03762. Available online: https://arxiv.org/abs/1706.03762 (accessed on 21 April 2020).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2020, arXiv:1810.04805. Available online: https://arxiv.org/abs/1810.04805 (accessed on 22 April 2020).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Amodei, D. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. Available online: https://arxiv.org/abs/2005.14165 (accessed on 22 August 2020).
- Payne, C. MuseNet. Available online: https://openai.com/blog/musenet (accessed on 23 April 2020).
- Yamamoto, R.; Song, E.; Kim, J.M. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6199–6203. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of Gans for Improved Quality, Stability, and Variation. arXiv 2020, arXiv:1710.10196. Available online: https://arxiv.org/abs/1710.10196 (accessed on 16 May 2020).
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. arXiv 2020, arXiv:1805.08318. Available online: https://arxiv.org/abs/1805.08318 (accessed on 17 May 2020).
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale Gan Training for High Fidelity Natural Image Synthesis. arXiv 2020, arXiv:1809.11096. Available online: https://arxiv.org/abs/1809.11096 (accessed on 20 May 2020).
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4401–4410. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of Trends in Practice and Research for Deep Learning. arXiv 2020, arXiv:1811.03378. Available online: https://arxiv.org/abs/1811.03378 (accessed on 22 May 2020).
- LeCun, Y.; Touresky, D.; Hinton, G.; Sejnowski, T. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School, San Mateo, CA, USA, 1 June 1988; Volume 1, pp. 21–28. [Google Scholar]
- Triola, M.F. Bayes’ Theorem. Available online: http://faculty.washington.edu/tamre/BayesTheorem.pdf (accessed on 10 January 2020).
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Gan. arXiv 2020, arXiv:1701.07875. Available online: https://arxiv.org/abs/1701.07875 (accessed on 25 May 2020).
- Gouk, H.; Frank, E.; Pfahringer, B.; Cree, M. Regularisation of Neural Networks by Enforcing Lipschitz Continuity. arXiv 2020, arXiv:1804.04368. Available online: https://arxiv.org/abs/1804.04368 (accessed on 26 May 2020).
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 5767–5777. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2020, arXiv:1502.03167. Available online: https://arxiv.org/abs/1502.03167 (accessed on 28 May 2020).
برای دانلود پروژه نمونه شبیه سازی مه با استفاده از شبکه های متخاصم مولد (GAN) به همراه شبیه سازی، اینجا کلیک کنید.
پروژه مشابه دارید؟
برای ثبت سفارش در سیمیا می توانید از طریق اپلیکیشن سیمیا، یا فرم ثبت سفارش در سایت اقدام کرده و یا از طریق ایمیل، واتساپ، تلگرام و اینستاگرام اقدام نمایید.
اپلیکیشن سیمیا را از بازار و مایکت دانلود کنید.
سریع ترین راه پاسخگویی سیمیا، واتساپ و سروش می باشد. لینک واتساپ، اینستاگرام و تلگرام در پایین سایت وجود دارد.
09392265610
نشانی ایمیل سیمیا simiya_ht@yahoo.com می باشد.
از برقراری تماس برای هماهنگی پروژه خودداری کنید، حجم بالای سفارشات به ما اجازه نمی دهد تا از طریق تلفن پاسخگوی شما عزیزان باشیم، حتما درخواست خود را به صورت مکتوب و از طریق یکی از راه های ذکر شده فوق ارسال نمایید، درخواست خود را به طور کامل و با تمام فایل ها و توضیحات لازم ارسال نمایید تا مدت زمان بررسی آن به حداقل برسد. پس از تعیین کارشناس، در اسرع وقت به شما پاسخ می دهیم.