هوش مصنوعی و بازی های ویدئویی
در بازیهای ویدیویی، تکنیکهای مختلف هوش مصنوعی به روشهای مختلف، از کنترل شخصیتهای غیربازیکن (NPC) تا تولید محتوای رویهای (PCG) استفاده شده است. یادگیری ماشینی زیرمجموعهای از هوش مصنوعی است که بر استفاده از الگوریتمها و مدلهای آماری برای وادار کردن ماشینها بدون برنامهنویسی خاص تمرکز دارد. این در تضاد شدید با روش های سنتی هوش مصنوعی مانند درختان جستجو و سیستم های خبره است.
اطلاعات مربوط به تکنیکهای یادگیری ماشین در زمینه بازیها عمدتاً از طریق پروژههای تحقیقاتی برای عموم شناخته میشود، زیرا اکثر شرکتهای بازی تصمیم میگیرند اطلاعات خاصی در مورد مالکیت معنوی خود منتشر نکنند. شناخته شده ترین کاربرد عمومی یادگیری ماشین در بازی ها احتمالاً استفاده از عوامل یادگیری عمیق است که با بازیکنان انسانی حرفه ای در بازی های استراتژی پیچیده رقابت می کنند. کاربرد قابل توجهی از یادگیری ماشین در بازی هایی مانند Atari/ALE، Doom، Minecraft، StarCraft و اتومبیل رانی وجود داشته است.[1] بازیهای دیگری که در ابتدا به عنوان بازیهای ویدیویی وجود نداشتند، مانند شطرنج و Go نیز تحت تأثیر یادگیری ماشینی قرار گرفتهاند.[2]

مروری بر تکنیک های یادگیری ماشین مربوطه
یادگیری عمیق
یادگیری عمیق زیرمجموعه ای از یادگیری ماشینی است که به شدت بر استفاده از شبکه های عصبی مصنوعی (ANN) تمرکز دارد که حل وظایف پیچیده را یاد می گیرند. یادگیری عمیق از چندین لایه ANN و تکنیک های دیگر برای استخراج تدریجی اطلاعات از یک ورودی استفاده می کند. با توجه به این رویکرد لایهای پیچیده، مدلهای یادگیری عمیق اغلب به ماشینهای قدرتمندی برای آموزش و اجرا نیاز دارند.


شبکه های عصبی کانولوشنال
شبکه های عصبی کانولوشنال (CNN) شبکه های عصبی مصنوعی تخصصی هستند که اغلب برای تجزیه و تحلیل داده های تصویر استفاده می شوند. این نوع شبکه ها قادر به یادگیری الگوهای تغییر ناپذیر ترجمه هستند که الگوهایی هستند که وابسته به مکان نیستند. CNN ها می توانند این الگوها را در یک سلسله مراتب بیاموزند، به این معنی که لایه های کانولوشنال قبلی الگوهای محلی کوچک تری را یاد می گیرند در حالی که لایه های بعدی الگوهای بزرگتر را بر اساس الگوهای قبلی می آموزند.[3] توانایی CNN برای یادگیری داده های بصری، آن را به ابزاری رایج برای یادگیری عمیق در بازی ها تبدیل کرده است.[4][5]
شبکه عصبی مکرر
شبکههای عصبی مکرر نوعی ANN هستند که برای پردازش دنبالهای از دادهها به ترتیب، یک قسمت در یک زمان و نه همه در یک زمان طراحی شدهاند. یک RNN روی هر قسمت از یک دنباله اجرا می شود و از قسمت فعلی دنباله همراه با حافظه قسمت های قبلی دنباله جاری برای تولید خروجی استفاده می کند. این نوع از ANN در کارهایی مانند تشخیص گفتار و سایر مشکلاتی که به شدت به ترتیب زمانی بستگی دارد بسیار موثر هستند. انواع مختلفی از RNN با تنظیمات داخلی مختلف وجود دارد. پیاده سازی اصلی به دلیل مشکل گرادیان ناپدید شدن از کمبود حافظه بلند مدت رنج می برد، بنابراین به ندرت در اجرای جدیدتر استفاده می شود.[3]


حافظه کوتاه مدت طولانی
یک شبکه حافظه کوتاه مدت طولانی (LSTM) یک پیاده سازی خاص از یک RNN است که برای مقابله با مشکل گرادیان محو مشاهده شده در RNN های ساده طراحی شده است، که منجر به فراموشی تدریجی آنها در مورد قسمت های قبلی یک دنباله ورودی در هنگام محاسبه می شود. خروجی یک قطعه فعلی LSTM ها این مشکل را با افزودن یک سیستم پیچیده که از یک ورودی/خروجی اضافی برای پیگیری داده های بلند مدت استفاده می کند، حل می کند.[3] LSTM به نتایج بسیار قوی در زمینه های مختلف دست یافته است و توسط چندین عامل یادگیری عمیق در بازی ها استفاده می شود.[6][4]
یادگیری تقویتی
یادگیری تقویتی فرآیند آموزش یک عامل با استفاده از پاداش و/یا تنبیه است. نحوه پاداش یا تنبیه یک مامور به شدت به مشکل بستگی دارد. مانند دادن پاداش مثبت به یک نماینده برای برنده شدن در یک بازی یا یک جایزه منفی برای باخت. یادگیری تقویتی به شدت در زمینه یادگیری ماشین استفاده می شود و می توان آن را در روش هایی مانند یادگیری Q، جستجوی خط مشی، شبکه های Deep Q و موارد دیگر مشاهده کرد. هم در زمینه بازی و هم در زمینه رباتیک عملکرد قوی داشته است.[7]
تکامل عصبی
Neuroevolution شامل استفاده از شبکه های عصبی و الگوریتم های تکاملی است. مدلهای تکامل عصبی به جای استفاده از شیب نزولی مانند اکثر شبکههای عصبی، از الگوریتمهای تکاملی برای بهروزرسانی نورونها در شبکه استفاده میکنند. محققان ادعا میکنند که این فرآیند کمتر در حداقل محلی گیر میکند و به طور بالقوه سریعتر از تکنیکهای جدید یادگیری عمیق است.[8]
عوامل یادگیری عمیق
عوامل یادگیری ماشینی به جای عملکرد به عنوان NPCها، که به عمد به عنوان بخشی از گیم پلی طراحی شده به بازی های ویدیویی اضافه می شوند، برای جایگزین کردن یک بازیکن انسانی استفاده شده است. عوامل یادگیری عمیق زمانی که در رقابت با انسان ها و سایر عوامل هوش مصنوعی استفاده می شوند به نتایج چشمگیری دست یافته اند.[2][9]
شطرنج
شطرنج یک بازی استراتژی نوبتی است که به دلیل پیچیدگی محاسباتی فضای تخته آن، یک مشکل هوش مصنوعی دشوار در نظر گرفته می شود. بازی های استراتژی مشابه اغلب با نوعی جستجوی درختی Minimax حل می شوند. این نوع از عوامل هوش مصنوعی برای شکست دادن بازیکنان حرفه ای شناخته شده اند، مانند مسابقه تاریخی Deep Blue در سال 1997 در مقابل گری کاسپاروف. از آن زمان، عوامل یادگیری ماشینی موفقیت بیشتری نسبت به عوامل قبلی هوش مصنوعی نشان دادهاند.
Go
Go یکی دیگر از بازی های استراتژی نوبتی است که مشکل هوش مصنوعی حتی دشوارتر از شطرنج در نظر گرفته می شود. فضای حالت is Go حدود 10^170 حالت تخته ممکن است در مقایسه با 10^120 حالت تخته شطرنج. قبل از مدلهای یادگیری عمیق اخیر، عوامل AI Go فقط میتوانستند در سطح یک انسان آماتور بازی کنند.[5]
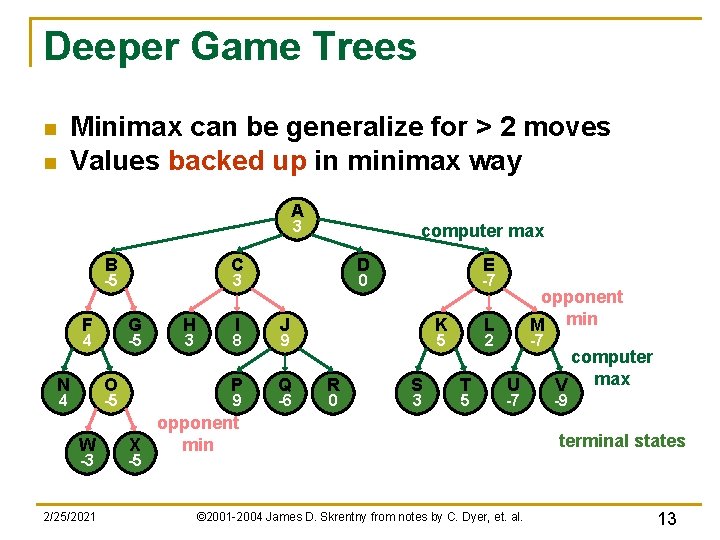
AlphaGo
AlphaGo 2015 گوگل اولین عامل هوش مصنوعی بود که یک بازیکن حرفه ای Go را شکست داد.[5] AlphaGo از یک مدل یادگیری عمیق برای آموزش وزن های جستجوی درخت مونت کارلو (MCTS) استفاده کرد. مدل یادگیری عمیق شامل 2 ANN، یک شبکه سیاست برای پیشبینی احتمالات حرکات بالقوه توسط مخالفان، و یک شبکه ارزش برای پیشبینی شانس پیروزی در یک وضعیت معین بود. مدل یادگیری عمیق به عامل اجازه می دهد تا حالت های بالقوه بازی را به طور موثرتری نسبت به MCTS وانیلی کشف کند. این شبکه در ابتدا بر روی بازیهای بازیکنان انسان آموزش داده شد و سپس توسط بازیهایی که علیه خود بازی میکردند بیشتر آموزش دیدند.
AlphaGo Zero
AlphaGo Zero، یکی دیگر از پیاده سازی های AlphaGo، توانست به طور کامل با بازی در برابر خودش تمرین کند. توانست به سرعت توانایی های عامل قبلی را آموزش دهد.[10]
سری StarCraft
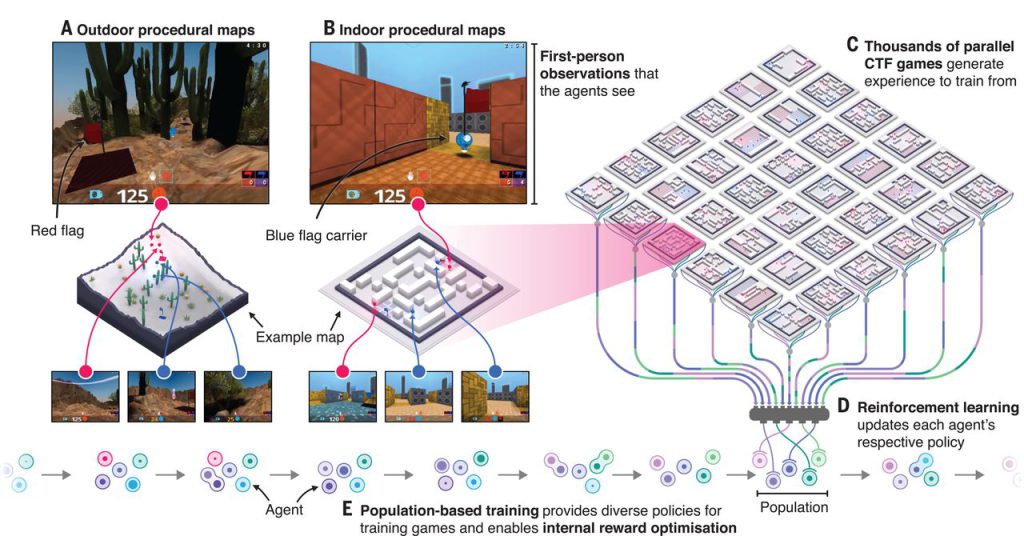
StarCraft و دنباله آن StarCraft II بازی های ویدیویی استراتژی زمان واقعی (RTS) هستند که به محیط های محبوبی برای تحقیقات هوش مصنوعی تبدیل شده اند. بلیزارد و دیپ مایند با هم کار کرده اند تا محیط عمومی StarCraft 2 را برای تحقیقات هوش مصنوعی منتشر کنند.[11] روشهای یادگیری عمیق مختلف روی هر دو بازی آزمایش شدهاند، اگرچه اکثر عوامل معمولاً در عملکرد بهتر از هوش مصنوعی پیشفرض با تقلبها یا بازیکنان ماهر بازی مشکل دارند.[1]
آلفاستار
Alphastar اولین عامل هوش مصنوعی بود که بازیکنان حرفه ای StarCraft 2 را بدون هیچ مزیتی در بازی شکست داد. شبکه یادگیری عمیق عامل در ابتدا ورودی را از یک نسخه کوچکنمایی شده سادهشده از گیماستیت دریافت میکرد، اما بعداً برای بازی با دوربین مانند سایر بازیکنان انسانی بهروزرسانی شد. توسعه دهندگان کد یا معماری مدل خود را به صورت عمومی منتشر نکرده اند، اما چندین تکنیک پیشرفته یادگیری ماشین مانند یادگیری تقویتی عمیق رابطه ای، حافظه کوتاه مدت طولانی، خط مشی های رگرسیون خودکار، شبکه های اشاره گر و ارزش متمرکز را فهرست کرده اند. خط مبنا.[4] Alphastar در ابتدا با یادگیری نظارت شده آموزش دیده بود، آن را به تماشای بازپخش بسیاری از بازی های انسانی به منظور یادگیری استراتژی های اساسی. سپس در برابر نسخه های مختلف خود آموزش دید و از طریق یادگیری تقویتی بهبود یافت. نسخه نهایی بسیار موفقیت آمیز بود، اما فقط برای بازی بر روی یک نقشه خاص در یک تطبیق آینه پروتوس آموزش دید.
دوتا 2
Dota 2 یک بازی چند نفره آنلاین عرصه نبرد (MOBA) است. مانند سایر بازیهای پیچیده، عوامل هوش مصنوعی سنتی نتوانستهاند در سطح یک بازیکن حرفهای انسان رقابت کنند. تنها اطلاعات گسترده منتشر شده در مورد عوامل هوش مصنوعی که در Dota 2 تلاش شده است، عامل پنج یادگیری عمیق OpenAI است.
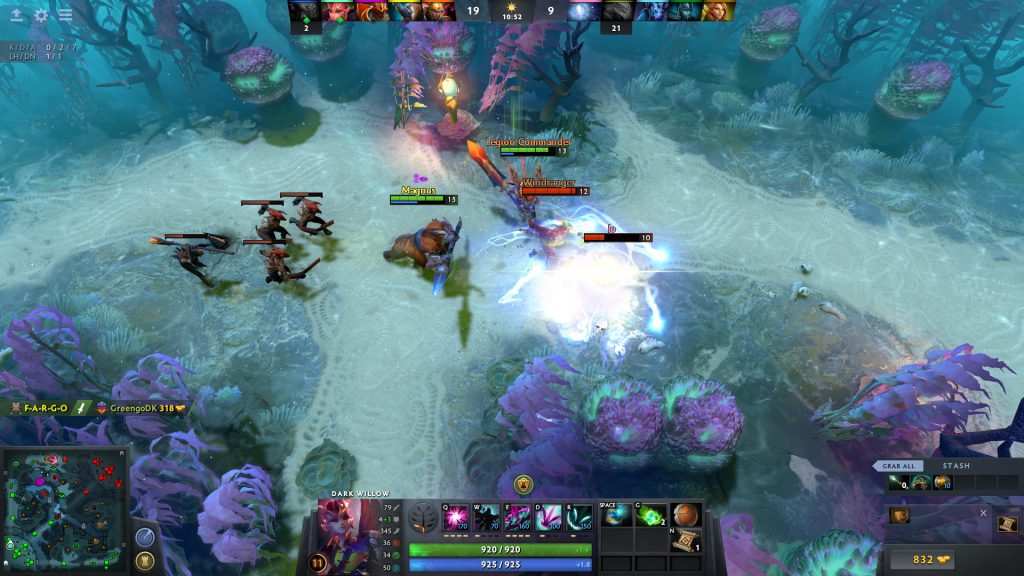
OpenAI Five
OpenAI Five از شبکه های LSTM جداگانه برای یادگیری هر قهرمان استفاده کرد. این سیستم با استفاده از تکنیک یادگیری تقویتی معروف به آموزش سیاست پروگزیمال که روی سیستمی حاوی 256 GPU و 128000 هسته CPU اجرا میشود، آموزش دید.[6] پنج نفر برای ماه ها تمرین کردند و 180 سال تجربه بازی را هر روز جمع کردند، قبل از رویارویی با بازیکنان حرفه ای.[12][13] در نهایت توانست در یک سری بازی در سال 2019 تیم قهرمان مسابقات الکترونیکی Dota 2 2018 را شکست دهد.
نابودی سیاره ای
Planetary Annihilation یک بازی استراتژیک بلادرنگ است که بر جنگ در مقیاس عظیم تمرکز دارد. توسعه دهندگان از ANN در عامل پیش فرض هوش مصنوعی خود استفاده می کنند.[14]
Supreme Commander 2
Supreme Commander 2 یک بازی ویدیویی استراتژی زمان واقعی (RTS) است. این بازی از پرسپترون های چندلایه (MLPs) برای کنترل واکنش جوخه به واحدهای دشمن استفاده می کند. در مجموع از چهار MLP استفاده می شود، یکی برای هر دسته جوخه: زمینی، دریایی، بمب افکن و جنگنده. [15]
بازی های تعمیم یافته
تلاش هایی برای ساخت عوامل یادگیری ماشینی صورت گرفته است که قادر به انجام بیش از یک بازی هستند. این عوامل بازی “عمومی” برای درک بازی ها بر اساس ویژگی های مشترک بین آنها آموزش دیده اند.
AlphaZero
AlphaZero یک نسخه تغییر یافته از AlphaGo Zero است که قادر به بازی Shogi، شطرنج و Go است. عامل تغییر یافته تنها با قوانین اساسی بازی شروع می کند و همچنین به طور کامل از طریق خودآموزی آموزش می بیند. DeepMind توانست این عامل تعمیم یافته را برای رقابت با نسخه های قبلی خود در Go و همچنین عوامل برتر در دو بازی دیگر آموزش دهد.[2]
نقاط قوت و ضعف عوامل یادگیری عمیق
عوامل یادگیری ماشین اغلب در بسیاری از دوره های طراحی بازی پوشش داده نمی شوند. استفاده قبلی از عوامل یادگیری ماشین در بازیها ممکن است چندان کاربردی نبوده باشد، زیرا حتی نسخه 2015 AlphaGo صدها CPU و GPU را برای آموزش به سطح قوی نیاز داشت.[2] این امر به طور بالقوه ایجاد عوامل یادگیری عمیق بسیار موثر را به شرکت های بزرگ یا افراد بسیار ثروتمند محدود می کند. زمان آموزش گسترده رویکردهای مبتنی بر شبکه عصبی نیز می تواند هفته ها در این ماشین های قدرتمند طول بکشد.[4]
مشکل آموزش موثر مدل های مبتنی بر ANN فراتر از محیط های سخت افزاری قدرتمند است. یافتن یک راه خوب برای نمایش داده ها و یادگیری چیزهای معنی دار از آن نیز اغلب یک مشکل دشوار است. مدلهای ANN اغلب برای دادههای بسیار خاص بیش از حد مناسب هستند و در موارد تعمیمیافتهتر عملکرد ضعیفی دارند. AlphaStar این ضعف را نشان میدهد، علیرغم اینکه میتواند بازیکنان حرفهای را شکست دهد، اما فقط میتواند این کار را در یک نقشه تنها در هنگام بازی mirror protoss matchup انجام دهد.[4] OpenAI Five نیز این ضعف را نشان میدهد، تنها زمانی که با یک استخر قهرمان بسیار محدود از کل بازی روبرو میشد، توانست بازیکن حرفهای را شکست دهد.[13] این مثال نشان میدهد که آموزش یک عامل یادگیری عمیق برای عملکرد در موقعیتهای کلیتر چقدر میتواند دشوار باشد.
عوامل یادگیری ماشین موفقیت زیادی در بازیهای مختلف نشان دادهاند.[12][2][4] با این حال، عواملی که بیش از حد صلاحیت دارند نیز خطر می کنند که بازی ها را برای بازیکنان جدید یا معمولی بسیار دشوار کنند. تحقیقات نشان داده است که چالش بسیار بالاتر از سطح مهارت بازیکن، لذت کمتر بازیکن را از بین می برد.[16] این عوامل بسیار آموزش دیده احتمالاً فقط در برابر بازیکنان انسانی بسیار ماهری که چندین ساعت تجربه در یک بازی خاص دارند، مطلوب هستند. با توجه به این عوامل، عوامل یادگیری عمیق بسیار مؤثر احتمالاً تنها در بازیهایی که صحنه رقابتی بزرگی دارند، انتخاب مطلوبی هستند، جایی که میتوانند به عنوان یک گزینه تمرین جایگزین برای یک بازیکن انسانی ماهر عمل کنند.
بازیکنان مبتنی بر بینایی کامپیوتری
بینایی کامپیوتر بر آموزش کامپیوترها برای به دست آوردن درک سطح بالایی از تصاویر یا فیلم های دیجیتال تمرکز دارد. بسیاری از تکنیکهای بینایی کامپیوتری اشکالی از یادگیری ماشینی را در خود جای دادهاند و در بازیهای ویدیویی مختلف به کار رفتهاند. این برنامه بینایی کامپیوتری بر تفسیر رویدادهای بازی با استفاده از داده های بصری تمرکز دارد. در برخی موارد، عوامل هوش مصنوعی از تکنیکهای بدون مدل برای یادگیری انجام بازیها بدون ارتباط مستقیم با منطق داخلی بازی استفاده میکنند و صرفاً از دادههای ویدیویی به عنوان ورودی استفاده میکنند.
پنگ
آندری کارپاتی نشان داده است که شبکه عصبی نسبتاً پیش پاافتاده با تنها یک لایه پنهان قادر به آموزش بازی پونگ تنها بر اساس داده های صفحه نمایش است.[17][18]
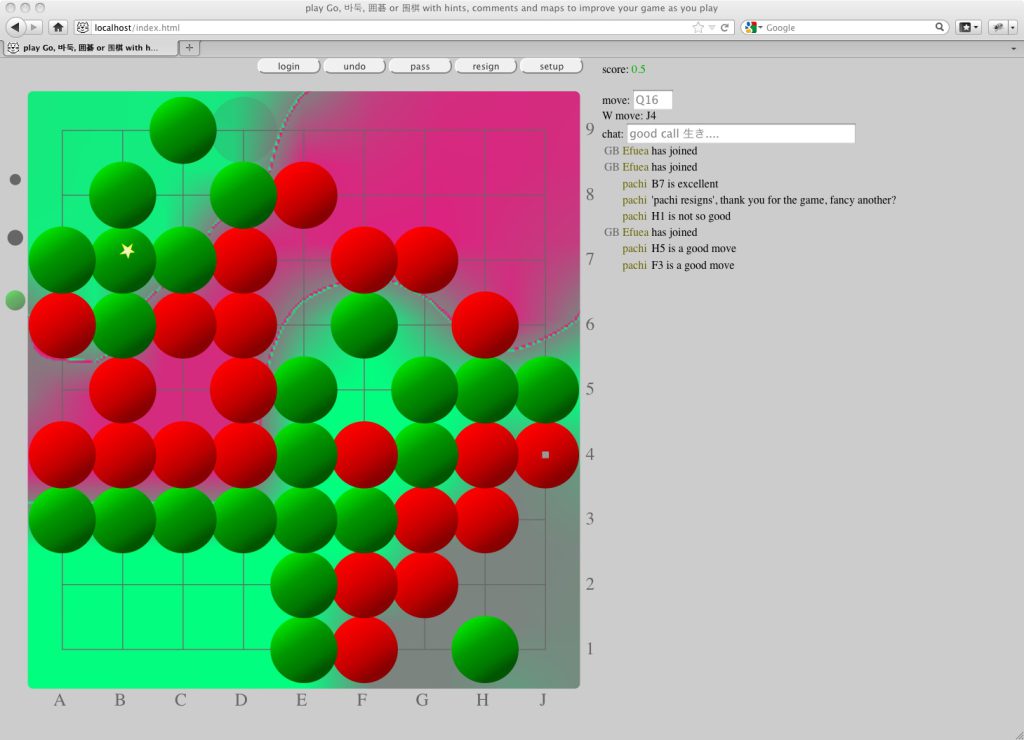
بازی های آتاری
در سال 2013، تیمی در DeepMind استفاده از یادگیری عمیق Q را برای اجرای انواع بازیهای ویدیویی آتاری – Beamrider، Breakout، Enduro، Pong، Q*bert، Seaquest، و Space Invaders – از دادههای صفحه نمایش نشان دادند.[19] این تیم کار خود را برای ایجاد یک الگوریتم یادگیری به نام MuZero گسترش داد که قادر به “یادگیری” قوانین و توسعه استراتژی های برنده برای بیش از 50 بازی مختلف Atari بر اساس داده های صفحه نمایش بود.[20][21]
Doom
Doom (1993) یک بازی تیراندازی اول شخص (FPS) است. محققان دانشجویی از دانشگاه کارنگی ملون از تکنیکهای بینایی کامپیوتری برای ایجاد عاملی استفاده کردند که بتواند بازی را تنها با استفاده از ورودی پیکسل تصویر از بازی انجام دهد. دانشآموزان از لایههای شبکه عصبی کانولوشن (CNN) برای تفسیر دادههای تصویر ورودی و خروجی اطلاعات معتبر به یک شبکه عصبی مکرر که مسئول خروجیگیری حرکات بازی بود، استفاده کردند.[22]
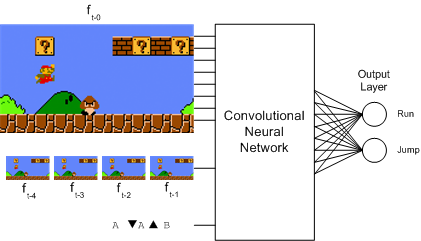
سوپر ماریو
سایر استفادههای تکنیکهای یادگیری عمیق مبتنی بر بینایی برای انجام بازیها شامل بازی Super Mario Bros فقط با استفاده از ورودی تصویر، استفاده از یادگیری عمیق Q برای آموزش است.[17]
ماین کرافت
محققان با OpenAI حدود 2000 ساعت پخش ویدئویی از Minecraft با ورودیهای انسانی لازم را ایجاد کردند و سپس یک مدل یادگیری ماشینی را برای درک بازخورد ویدیویی از ورودی آموزش دادند. سپس محققان از آن مدل با 70000 ساعت بازی Minecraft که در یوتیوب ارائه شده بود استفاده کردند تا ببینند این مدل چقدر میتواند ورودی را برای مطابقت با آن رفتار ایجاد کند و از آن بیشتر بیاموزد، مانند توانایی یادگیری مراحل و فرآیند ایجاد یک ابزار کلنگ الماس. [23][24]
یادگیری ماشینی برای تولید محتوای رویه ای در بازی ها
یادگیری ماشینی تحقیقاتی را برای استفاده در توصیه و تولید محتوا انجام داده است. تولید محتوای رویه ای فرآیند ایجاد داده ها به صورت الگوریتمی و نه دستی است. این نوع محتوا برای افزودن قابلیت پخش مجدد به بازی ها بدون تکیه بر افزودن های مداوم توسط توسعه دهندگان انسانی استفاده می شود. PCG در بازیهای مختلف برای انواع مختلف تولید محتوا استفاده شده است، نمونههایی از آنها شامل سلاحها در Borderlands 2، [25] همه طرحبندیهای جهان در Minecraft [26] و کل جهانها در No Man’s Sky است.[27] رویکردهای رایج PCG شامل تکنیک هایی است که شامل دستور زبان، الگوریتم های مبتنی بر جستجو و برنامه نویسی منطقی می شود.[28] این رویکردها از انسان ها می خواهند که به صورت دستی محدوده محتوای ممکن را تعریف کنند، به این معنی که یک توسعه دهنده انسانی تصمیم می گیرد که چه ویژگی هایی یک قطعه معتبر از محتوای تولید شده را تشکیل می دهد. یادگیری ماشینی از نظر تئوری قادر به یادگیری این ویژگیها است که مثالهایی برای آموزش داده شود، بنابراین مرحله پیچیده توسعهدهندگان برای تعیین جزئیات طراحی محتوا تا حد زیادی کاهش مییابد.[29] تکنیکهای یادگیری ماشینی که برای تولید محتوا استفاده میشوند عبارتند از: حافظه کوتاهمدت (LSTM)، شبکههای عصبی تکراری (RNN)، شبکههای متخاصم مولد (GAN)، و خوشهبندی K-means. همه این تکنیکها از شبکههای عصبی مصنوعی استفاده نمیکنند، اما توسعه سریع یادگیری عمیق، پتانسیل تکنیکهایی را که این کار را انجام میدهند بسیار افزایش داده است.[29]

مسابقه تسلیحاتی کهکشانی
مسابقه تسلیحاتی کهکشانی یک بازی ویدئویی تیراندازی فضایی است که از PCG مبتنی بر تکامل عصبی برای تولید سلاح های منحصر به فرد برای بازیکن استفاده می کند. این بازی در سال 2010 فینالیست بازی Indie Challenge بود و مقاله تحقیقاتی مرتبط با آن برنده جایزه بهترین مقاله در کنفرانس IEEE در سال 2009 در زمینه هوش محاسباتی و بازی ها شد. توسعه دهندگان از نوعی تکامل عصبی به نام cgNEAT برای تولید محتوای جدید بر اساس ترجیحات شخصی هر بازیکن استفاده می کنند.[30]
هر آیتم تولید شده توسط یک ANN خاص که به عنوان شبکه تولید الگوی ترکیبی (CPPN) شناخته می شود، نشان داده می شود. در طول مرحله تکاملی بازی، cgNEAT تناسب آیتمهای فعلی را بر اساس میزان استفاده بازیکن و سایر معیارهای گیمپلی محاسبه میکند، سپس از این امتیاز تناسب اندام استفاده میشود تا تصمیم بگیرید کدام CPPN برای ایجاد یک آیتم جدید بازتولید شود. نتیجه نهایی تولید افکت های سلاح جدید بر اساس ترجیح بازیکن است.
برادران سوپر ماریو
Super Mario Bros توسط چندین محقق برای شبیه سازی ایجاد سطح PCG استفاده شده است. تلاش های مختلف با استفاده از روش های مختلف. نسخه ای در سال 2014 از n-gram برای تولید سطوحی مشابه سطوحی که در آن آموزش دیده بود استفاده کرد که بعداً با استفاده از MCTS برای هدایت تولید بهبود یافت.[31] این نسلها اغلب هنگام در نظر گرفتن معیارهای گیمپلی مانند حرکت بازیکن بهینه نبودند، یک پروژه تحقیقاتی جداگانه در سال 2017 سعی کرد این مشکل را با ایجاد سطوح بر اساس حرکت بازیکن با استفاده از زنجیرههای مارکوف حل کند.[32] این پروژه ها تحت آزمایش انسانی قرار نگرفته اند و ممکن است استانداردهای بازی پذیری انسانی را رعایت نکنند.
افسانه ی زلدا
ایجاد سطح PCG برای The Legend of Zelda توسط محققان دانشگاه کالیفرنیا، سانتا کروز انجام شده است. این تلاش از شبکه بیزی برای یادگیری دانش سطح بالا از سطوح موجود استفاده کرد، در حالی که تجزیه و تحلیل مؤلفه اصلی (PCA) برای نشان دادن ویژگیهای سطح پایین مختلف این سطوح استفاده شد.[33] محققان از PCA برای مقایسه سطوح تولید شده با سطوح ساخته شده توسط انسان استفاده کردند و دریافتند که آنها بسیار مشابه در نظر گرفته می شوند. این تست شامل قابلیت پخش یا آزمایش انسانی سطوح تولید شده نمیشود.
نسل موسیقی
موسیقی اغلب در بازیهای ویدیویی دیده میشود و میتواند عنصری حیاتی برای تأثیرگذاری بر خلق و خوی موقعیتها و نکات داستانی مختلف باشد. یادگیری ماشینی در زمینه تجربی تولید موسیقی کاربرد داشته است. این به طور منحصر به فرد برای پردازش داده های بدون ساختار خام و تشکیل نمایش های سطح بالا که می تواند در زمینه های متنوع موسیقی اعمال شود، مناسب است.[34] بیشتر روش های تلاش شده شامل استفاده از ANN به شکلی بوده است. روشها شامل استفاده از شبکههای عصبی پیشخور اولیه، رمزگذارهای خودکار، ماشینهای بولتزمن محدود، شبکههای عصبی تکراری، شبکههای عصبی کانولوشنال، شبکههای متخاصم مولد (GAN) و معماریهای ترکیبی است که از روشهای متعدد استفاده میکنند.[34]

سیستم تولید موسیقی نمادین ملودی بازی ویدیویی VRAE
مقاله تحقیقاتی در سال 2014 در مورد “رمزگذارهای خودکار تکراری متغیر” تلاش کرد تا موسیقی را بر اساس آهنگ های 8 بازی ویدیویی مختلف تولید کند. این پروژه یکی از معدود پروژه هایی است که صرفاً بر روی موسیقی بازی های ویدیویی انجام شده است. شبکه عصبی در این پروژه قادر به تولید دادههایی بود که بسیار شبیه به دادههای بازیهایی بود که در آنها آموزش دیده بود.[35] داده های تولید شده به موسیقی با کیفیت خوب ترجمه نشد.
منابع
- Justesen, Niels; Bontrager, Philip; Togelius, Julian; Risi, Sebastian (2019). “Deep Learning for Video Game Playing”. IEEE Transactions on Games. 12: 1–20. arXiv:1708.07902. doi:10.1109/tg.2019.2896986. ISSN2475-1502. S2CID37941741. Silver, David; Hubert, Thomas; Schrittwieser, Julian; Antonoglou, Ioannis; Lai, Matthew; Guez, Arthur; Lanctot, Marc; Sifre, Laurent; Kumaran, Dharshan (2018-12-06). “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play” (PDF). Science. 362 (6419): 1140–1144. Bibcode:2018Sci…362.1140S. doi:10.1126/science.aar6404. ISSN0036-8075. PMID30523106. S2CID54457125. Chollet, Francois (2017-10-28). Deep learning with Python. ISBN9781617294433. OCLC1019988472. “AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”. DeepMind. Retrieved 2019-06-04. Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; van den Driessche, George; Schrittwieser, Julian; Antonoglou, Ioannis; Panneershelvam, Veda (January 2016). “Mastering the game of Go with deep neural networks and tree search”. Nature. 529 (7587): 484–489. Bibcode:2016Natur.529..484S. doi:10.1038/nature16961. ISSN0028-0836. PMID26819042. S2CID515925. “OpenAI Five”. OpenAI. 2018-06-25. Retrieved 2019-06-04. Russell, Stuart J. (Stuart Jonathan) (2015). Artificial intelligence : a modern approach. Norvig, Peter (Third Indian ed.). Noida, India. ISBN9789332543515. OCLC928841872. Clune, Jeff; Stanley, Kenneth O.; Lehman, Joel; Conti, Edoardo; Madhavan, Vashisht; Such, Felipe Petroski (2017-12-18). “Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning”. arXiv:1712.06567 [cs.NE]. Zhen, Jacky Shunjie; Watson, Ian (2013), “Neuroevolution for Micromanagement in the Real-Time Strategy Game Starcraft: Brood War”, Lecture Notes in Computer Science, Springer International Publishing, pp. 259–270, CiteSeerX10.1.1.703.5110, doi:10.1007/978-3-319-03680-9_28, ISBN9783319036793 Silver, David; Schrittwieser, Julian; Simonyan, Karen; Antonoglou, Ioannis; Huang, Aja; Guez, Arthur; Hubert, Thomas; Baker, Lucas; Lai, Matthew (October 2017). “Mastering the game of Go without human knowledge” (PDF). Nature. 550 (7676): 354–359. Bibcode:2017Natur.550..354S. doi:10.1038/nature24270. ISSN0028-0836. PMID29052630. S2CID205261034. Tsing, Rodney; Repp, Jacob; Ekermo, Anders; Lawrence, David; Brunasso, Anthony; Keet, Paul; Calderone, Kevin; Lillicrap, Timothy; Silver, David (2017-08-16). “StarCraft II: A New Challenge for Reinforcement Learning”. arXiv:1708.04782 [cs.LG]. “OpenAI Five”. OpenAI. Retrieved 2019-06-04. “How to Train Your OpenAI Five”. OpenAI. 2019-04-15. Retrieved 2019-06-04. xavdematos. “Meet the computer that’s learning to kill and the man who programmed the chaos”. Engadget. Retrieved 2019-06-04. http://www.gameaipro.com/GameAIPro/GameAIPro_Chapter30_Using_Neural_Networks_to_Control_Agent_Threat_Response.pdf[bare URL PDF] Sweetser, Penelope; Wyeth, Peta (2005-07-01). “GameFlow”. Computers in Entertainment. 3 (3): 3. doi:10.1145/1077246.1077253. ISSN1544-3574. S2CID2669730. Jones, M. Tim (June 7, 2019). “Machine learning and gaming”. IBM Developer. Retrieved 2020-02-03. “Deep Reinforcement Learning: Pong from Pixels”. karpathy.github.io. Retrieved 2020-02-03. Mnih, Volodymyr; Kavukcuoglu, Koray; Silver, David; Graves, Alex; Antonoglou, Ioannis; Wierstra, Daan; Riedmiller, Martin (2013-12-19). “Playing Atari with Deep Reinforcement Learning”. arXiv:1312.5602 [cs.LG]. Bonifacic, Igor (December 23, 2020). “DeepMind’s latest AI can master games without being told their rules”. Engadget. Retrieved December 23, 2020. Schrittwieser, Julian; Antonoglou, Ioannis; Hubert, Thomas; Simonyan, Karen; Sifre, Laurent; Schmitt, Simon; Guez, Arthur; Lockhart, Edward; Hassabis, Demis; Graepel, Thore; Lillicrap, Timothy; Silver, David (2020). “Mastering Atari, Go, chess and shogi by planning with a learned model”. Nature. 588 (7839): 604–609. arXiv:1911.08265. Bibcode:2020Natur.588..604S. doi:10.1038/s41586-020-03051-4. PMID33361790. S2CID208158225. Lample, Guillaume; Chaplot, Devendra Singh (2017). “Playing FPS Games with Deep Reinforcement Learning”. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. AAAI’17. San Francisco, California, USA: AAAI Press: 2140–2146. arXiv:1609.05521. Bibcode:2016arXiv160905521L. Matthews, David (June 27, 2022). “An AI Was Trained To Play Minecraft With 70,000 Hours Of YouTube Videos”. IGN. Retrieved July 8, 2022. Baker, Bowen; Akkaya, Ilge; Zhokhov, Peter; Huizinga, Joost; Tang, Jie; Ecoffet, Adrien; Houghton, Brandon; Sampedro, Raul; Clune, Jeff (2022). “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”. arXiv:2206.11795 [cs.LG]. Yin-Poole, Wesley (2012-07-16). “How many weapons are in Borderlands 2?”. Eurogamer. Retrieved 2019-06-04. “Terrain generation, Part 1”. The Word of Notch. Retrieved 2019-06-04. Parkin, Simon. “A Science Fictional Universe Created by Algorithms”. MIT Technology Review. Retrieved 2019-06-04. Togelius, Julian; Shaker, Noor; Nelson, Mark J. (2016), “Introduction”, Procedural Content Generation in Games, Springer International Publishing, pp. 1–15, doi:10.1007/978-3-319-42716-4_1, ISBN9783319427140 Summerville, Adam; Snodgrass, Sam; Guzdial, Matthew; Holmgard, Christoffer; Hoover, Amy K.; Isaksen, Aaron; Nealen, Andy; Togelius, Julian (September 2018). “Procedural Content Generation via Machine Learning (PCGML)”. IEEE Transactions on Games. 10 (3): 257–270. arXiv:1702.00539. doi:10.1109/tg.2018.2846639. ISSN2475-1502. S2CID9950600. Hastings, Erin J.; Guha, Ratan K.; Stanley, Kenneth O. (September 2009). “Evolving content in the Galactic Arms Race video game” (PDF). 2009 IEEE Symposium on Computational Intelligence and Games. IEEE: 241–248. doi:10.1109/cig.2009.5286468. ISBN9781424448142. S2CID16598064. Summerville, Adam. “MCMCTS PCG 4 SMB: Monte Carlo Tree Search to Guide Platformer Level Generation”. www.aaai.org. Retrieved 2019-06-04. Snodgrass, Sam; Ontañón, Santiago (August 2017). “Player Movement Models for Video Game Level Generation”. Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence. California: International Joint Conferences on Artificial Intelligence Organization: 757–763. doi:10.24963/ijcai.2017/105. ISBN9780999241103. Summerville, James. “Sampling Hyrule: Multi-Technique Probabilistic Level Generation for Action Role Playing Games”. www.aaai.org. Retrieved 2019-06-04. Pachet, François-David; Hadjeres, Gaëtan; Briot, Jean-Pierre (2017-09-05). “Deep Learning Techniques for Music Generation – A Survey”. arXiv:1709.01620 [cs.SD]. van Amersfoort, Joost R.; Fabius, Otto (2014-12-20). “Variational Recurrent Auto-Encoders”. arXiv:1412.6581 [stat.ML].
برای دانلود پروژه نمونه استفاده از تولید محتوای رویه ای از طریق یادگیری ماشین به عنوان مکانیک بازی به همراه شبیه سازی، اینجا کلیک کنید.
پروژه مشابه دارید؟
برای ثبت سفارش در سیمیا می توانید از طریق اپلیکیشن سیمیا، یا فرم ثبت سفارش در سایت اقدام کرده و یا از طریق ایمیل، واتساپ، تلگرام و اینستاگرام اقدام نمایید.
اپلیکیشن سیمیا را از بازار و مایکت دانلود کنید.
سریع ترین راه پاسخگویی سیمیا، واتساپ و سروش می باشد. لینک واتساپ، اینستاگرام و تلگرام در پایین سایت وجود دارد.
09392265610
نشانی ایمیل سیمیا simiya_ht@yahoo.com می باشد.
از برقراری تماس برای هماهنگی پروژه خودداری کنید، حجم بالای سفارشات به ما اجازه نمی دهد تا از طریق تلفن پاسخگوی شما عزیزان باشیم، حتما درخواست خود را به صورت مکتوب و از طریق یکی از راه های ذکر شده فوق ارسال نمایید، درخواست خود را به طور کامل و با تمام فایل ها و توضیحات لازم ارسال نمایید تا مدت زمان بررسی آن به حداقل برسد. پس از تعیین کارشناس، در اسرع وقت به شما پاسخ می دهیم.