با ظهور فناوری یادگیری عمیق، فناوری تشخیص گفتار بیش از پیش بالغ شده است و حتی از دقت طبقهبندی مصنوعی در زمینههای طبقهبندی صدای انسان و طبقهبندی صدای موسیقی فراتر رفته است. با این حال، به عنوان بخش مهمی از تشخیص گفتار، طبقه بندی صدای محیطی هنوز با چالش های بزرگی مواجه است. ESC به طور گسترده در خانه های هوشمند، تجزیه و تحلیل صحنه، شنوایی ماشین و سایر زمینه ها استفاده می شود. هدف آن طبقه بندی دقیق دسته ای از صداهای شناسایی شده، مانند بوق ماشین، بیکار موتور، موسیقی خیابانی و غیره است. به دلیل ویژگی های غیر ثابت زیاد صدای محیط و تداخل شدید نویز محیطی، طبقه بندی آن دشوار است.
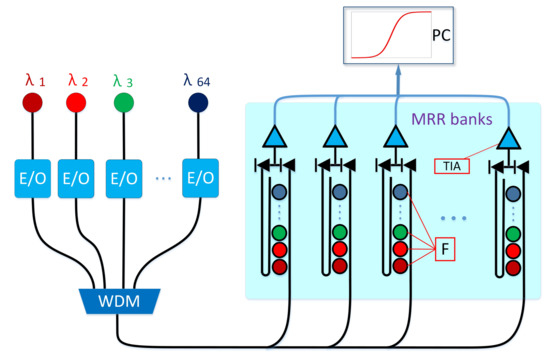
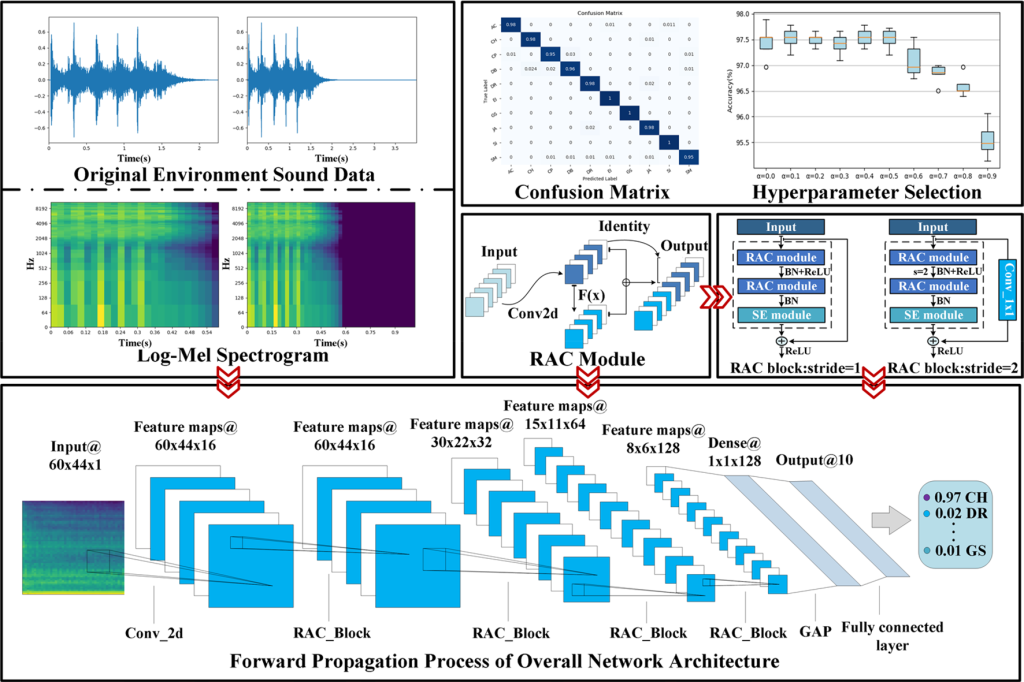
ESC عمدتاً شامل دو مرحله است: استخراج ویژگی صوتی و طبقهبندی. برای استخراج موثر ویژگیهای صوتی، لازم است سیگنال صوتی را به فریمها تقسیم کرده و سپس ویژگیهای هر فریم را استخراج کنیم. ضرایب مغزی فرکانس مل (MFCC) و طیف نگاری log-Mel دو ویژگی پرکاربرد در ESC هستند. در سالهای اولیه، ماشین بردار پشتیبانی (SVM) 1، 2، مدل مخلوط گاوسی (GMM)3، ماشین یادگیری افراطی (ELM) و سایر الگوریتمهای یادگیری ماشین معمولاً برای طبقهبندی ویژگیهای صدای استخراجشده استفاده میشدند. با این حال، این طبقهبندیکنندههای سنتی برای شبیهسازی تغییرات کوچک طراحی شدهاند که منجر به عدم تغییر زمان و فرکانس میشود. در سالهای اخیر، ثابت شده است که روش مبتنی بر شبکه عصبی عمیق (DNN) در حل مسائل پیچیده طبقهبندی مؤثرتر است و به تدریج جایگزین الگوریتم یادگیری ماشین سنتی شد. شبکه عصبی کانولوشن، به عنوان یکی از رایج ترین معماری های مورد استفاده در یادگیری عمیق، می تواند در زمان و فرکانس به طور همزمان از طریق عملیات کانولوشن یاد بگیرد، که محدودیت های الگوریتم یادگیری ماشین سنتی را حل می کند. در عین حال، CNN می تواند ویژگی های انتزاعی عمیق تری را برای طبقه بندی بر اساس ویژگی های دست ساز استخراج کند. اگرچه CNN عملکرد عالی دارد، اما بهبود عملکرد آن به تعداد زیادی پارامتر و FLOP بستگی دارد. تعداد زیاد پارامترها و محاسبات سرعت اجرای CNN را کاهش میدهد که برآوردن الزامات عملکرد زمان واقعی و استقرار در دستگاههای تعبیهشده که فاقد منابع ذخیرهسازی و محاسباتی هستند را دشوار میسازد. بنابراین، به منظور کاهش هزینه عملیات CNN و بهبود سرعت طبقهبندی صدای محیطی، RACNN را پیشنهاد میکنیم که هسته اصلی آن در ایده عملیات کانولوشن جدید نهفته است. ما آن را ماژول RAC می نامیم که نقشه های ویژگی اضافی را به روشی نسبتا ارزان تولید می کند. در مقایسه با عملیات کانولوشن سنتی، تعداد کانالهای مشابهی با هزینه ذخیرهسازی و عملیات کمتر تولید میکند و اطلاعات ویژگیهای فراوانتری را دریافت میکند. بر اساس آن، مکانیسم توجه دامنه کانال و اتصال پرش برای تولید یک بلوک استخراج ویژگی کارآمد ترکیب میشوند و RACNN به سادگی با انباشتن این بلوک تشکیل میشود. فرآیند خاص ESC با استفاده از RACNN در شکل 1 نشان داده شده است.

یادگیری عمیق به طور گسترده در زمینه های مختلف مورد استفاده قرار گرفته است. در سال های اخیر بسیاری از محققان این فناوری را وارد حوزه ESC کرده اند. در این فصل، روشهای یادگیری عمیق مورد استفاده در زمینههای مرتبط با ESC و تحقیقات اصلی در مورد فشردهسازی CNN را معرفی میکنیم.


اولین و رایجترین مدل CNN در زمینه ESC دو بعدی CNN است. Piczak4 برای اولین بار استفاده از CNN دو بعدی را برای یادگیری ویژگی های طیف نگار Log-Mel پیشنهاد کرد که عملکرد ESC را در مقایسه با الگوریتم های یادگیری ماشین سنتی مانند KNN و SVM به طور قابل توجهی بهبود بخشید. چن و همکاران 5 سیگنال صوتی وسیله نقلیه را با ادغام واحد LSTM در شبکه عصبی کانولوشنال به دقت شناسایی کردند. Boddapati و همکاران 6 از AlexNet7 و GoogLeNet8 برای طبقه بندی ویژگی های صدای محیطی استخراج شده از طیف استفاده می کنند. با این حال، این سیانان برای طبقهبندی مجموعه داده بزرگ تصویر-ImageNet در اولین زمان مورد استفاده قرار گرفت. بنابراین، این مدل ها به طور کامل برای کار ESC مناسب نیستند، که به راحتی باعث اضافه شدن بیش از حد، ناتوانی در ارائه کامل عملکرد CNN، ایجاد افزونگی پارامترها و کاهش سرعت می شود. متعاقباً، بسیاری از محققان شروع به مطالعه تأثیر ویژگیهای طیفنگاری مختلف بر نتایج طبقهبندی نهایی کردند. Tran و همکاران 9 SirenNet را پیشنهاد کردند و شکل موج های صوتی اصلی، MFCC و Log-Mel را به عنوان ورودی برای تشخیص وسایل نقلیه اضطراری بر اساس آژیرها ترکیب کردند. بعداً، سو و همکاران 10 از دو ویژگی ترکیبی (MFCC-CST و LM-CST) برای آموزش CNN (MCNet و LMCNet) استفاده کردند و سپس از نظریه شواهد Dempster-Shafer (DS) برای ترکیب CNN آموزش دیده توسط ویژگی های مختلف برای تشکیل TSCNN استفاده کردند. مدل -DS، که 97.2٪ دقت طبقه بندی را در مجموعه داده UrbanSound8K به دست آورد. Su و همکاران 11 عملکرد ESC را بر اساس ویژگی های آکوستیک چند تجمعی بیشتر تحلیل کردند. نویسنده از طریق تعداد زیادی آزمایش، بهترین استراتژی تجمیع ویژگی را در میان ترکیبهای ویژگی از جمله MFCC، Log-Mel، Chroma، Spectral Contrast و Tonnetz برای بهبود دقت ESC پیدا کرد. در نهایت، با ترکیب MFCC، Log-Mel، Spectral Contrast و Tonnetz، دقت ESC-50 و UrbanSound8K به ترتیب 85.6٪ و 93.4٪ است.
علاوه بر پرکاربردترین CNN دو بعدی، بسیاری از محققان وظایف ESC را از دیدگاه CNN 1-D انجام می دهند. Zhang و همکاران 12 یک روش ESC را بر اساس VGGNet13 پیشنهاد کردند و فیلتر کانولوشن را روی 1-D تنظیم کردند تا ویژگی های فرکانس و زمانی صدا را یاد بگیرند. دای و همکاران 14 یک مدل سیانان 1-بعدی 34 لایه را برای طبقهبندی دادههای شکل موج یکبعدی اولیه پیشنهاد کردند و دقت رقابتی را با CNN 2 بعدی بر اساس طیفنگار Log-Mel نشان دادند، اما به یک لایه پیچشی عمیقتر نیاز دارد. Abdoli و همکاران 15 یک روش ESC end-to-end را بر اساس CNN 1-D، بدون استخراج ویژگی مصنوعی پیشنهاد کردند. آنتونیو و همکاران 16 DENet را پیشنهاد کردند که از صدای اصلی بدون تلفات به عنوان ورودی استفاده میکرد و لایه پیشنهادی را با یک واحد بازگشتی دروازهدار دو طرفه ترکیب کرد تا جلوه طبقهبندی صوتی خوبی به دست آورد. فرانسیسکو و همکاران 17 معماری شبکه عصبی SinNet را توسعه دادند که از صدای خام برای طبقه بندی صداهای حیوانات استفاده می کند و در مورد داده های محدود به همگرایی سریع دست می یابد. دونگ و همکاران 18 یک شبکه عصبی کانولوشنال دو جریانی را پیشنهاد کردند. این مدل از CNN 1 بعدی بر اساس صدای خام و CNN 2 بعدی بر اساس طیفنگار Log-Mel تشکیل شده است. این ویژگیهای زمان و فرکانس صدا را ترکیب میکند و 95.7% دقت متوسط و 96.07% بالاترین دقت را در UrbanSound8K به دست میآورد.


برای اینکه تحقیقات مرتبط با ESC بهتر در خدمت کاربردهای عملی باشد، بر اساس این تحقیق، محققان تحقیقاتی را در مورد وظیفه محلیسازی و تشخیص رویداد صدا (SELD) انجام دادهاند. شیمادا و همکاران 19 چارچوب CRNN را پیشنهاد کردند که CNN و RNN را برای درک محلی سازی و تشخیص رویدادهای صوتی ترکیب می کند، اما عملکرد باید بهبود یابد. Nguyen و همکاران 20 شبکه ستون فقرات را در CRNN با VGG و ResNet جایگزین کردند و یک ویژگی جدید SALSA را پیشنهاد کردند که در نهایت به عملکرد عالی دست یافت. و نویسنده همچنین عملکرد ترکیبی از شبکه ستون فقرات و ساختارهای مختلف RNN را آزمایش کرد. Sun و همکاران 21 پیچیدگی هیبریدی تطبیقی را بر اساس ایده تجزیه ماتریس پیشنهاد کردند و ماژول توجه را برای به دست آوردن نتایج خوبی در کار SLED ترکیب کردند. Sudarsanam و همکاران 22 بلوک های RNN را در معماری CRNN با بلوک های خودتوجه جایگزین کردند. آنها همچنین انباشتن چندین بلوک خودتوجهی، استفاده از سرهای توجه متعدد در هر بلوک توجه به خود، و تعبیه موقعیت و عادی سازی لایه را بررسی کردند. با ظهور تحقیقات ترانسفورماتور، این ساختار برای SELD نیز اعمال شده است. Huang و همکاران 23 با استفاده از ترکیب CNN و Transformer عملکردی کمتر از CRNN به دست آوردند.
منابع
- Chu, S., Narayanan, S. & Kuo, C. C. J. Environmental sound recognition with time-frequency audio features. IEEE Trans. Audio Speech Language Process 17(6), 1142–1158 (2009).Article Google Scholar
- Wei, P., He, F., Li, L. & Li, J. Research on sound classification based on svm. Neural Comput. Appl.. 32, 1593–1607 (2020).Article Google Scholar
- Purwins, H. et al. Deep learning for audio signal processing. IEEE J. Sel. Top. Signal Process. 13(2), 206–219 (2019).Article ADS Google Scholar
- Piczak, K. J. Environmental sound classification with convolutional neural networks. In: Proc. 25th Int. Workshop Mach. Learning Signal Process, 1–6 (2015)
- Chen, H. & Zhang, Z. Hybrid neural network based on novel audio feature for vehicle type identifcation. Sci. Rep. 11, 7648 (2021).Article ADS CAS Google Scholar
- Boddapati, V., Petef, A., Rasmusson, J. & Lundberg, L. Classifying environmental sounds using image recognition networks. Procedia Comput. Sci. 112, 2048–2056 (2017).Article Google Scholar
- Krizhevsky, A., Sutskever. I., & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In NeurIPS, 1097–1105 (2012)
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., & Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1–9 (2015)
- Tran, V. T. & Tsai, W. H. Acoustic-based emergency vehicle detection using convolutional neural networks. IEEE Access 8, 75702–75713. https://doi.org/10.1109/ACCESS.2020.2988986 (2020).Article Google Scholar
- Su, Y., Zhang, K., Wang, J. & Madani, K. Environment sound classification using a two-stream cnn based on decision-level fusion. Sensors (Basel, Switzerland) 19(7), 1733 (2019).Article ADS Google Scholar
- Su, Y., Zhang, K., Wang, J. & Madani, K. Performance analysis of multiple aggregated acoustic features for environment sound classification. Appl. Acoust. 158, 107050 (2020).Article Google Scholar
- Zhang, Z., Xu, S., Cao, S., & Zhang, S. Deep convolutional neural network with mixup for environmental sound classification. In: Proc. Chinese Conf. Pattern Recognit. Comput. Vision, 356–367 (Springer, 2018)
- Simonyan, K., & Zisserman, A. Very deep convolutional networks for large-scale image recognition. In: ICLR (2015)
- Dai, W., Dai, C., Qu, S., Li, J., & Das, S. Very deep convolutional neural networks for raw waveforms. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 421–425 (2017)
- Abdoli, S., Cardinal, P. & Koerich, A. L. End-to-end environmental sound classification using a 1D convolutional neural network. Expert Syst. Appl. 136, 252–263. https://doi.org/10.1016/j.eswa.2019.06.040 (2019).Article Google Scholar
- Greco, A., Roberto, A., Saggese, A. & Vento, M. Denet: a deep architecture for audio surveillance applications. Neural Comput. Appl. 5, 1–12 (2021). Google Scholar
- Francisco, J., Bravo, S., Md, R., Nathan, B. & Steven, T. Bioacoustic classifcation of avian calls from raw sound waveforms with an open-source deep learning Architecture. Sci. Rep. 11, 15733 (2021).Article Google Scholar
- Dong, X., Yin, B. & Cong, Y. Environment sound event classification with a two-stream convolutional neural network. IEEE Access 99, 1–1 (2020).Article Google Scholar
- Adavanne, S., Politis, A., Nikunen, J. & Virtanen, T. Sound event localization and detection of overlapping sources using convolutional recurrent neural networks. IEEE J. Sel. Top. Signal Process. 13(1), 34–48 (2018).Article ADS Google Scholar
- Nguyen, T. N. T., Watcharasupat, K., Nguyen, N. K. N., Jones, D. L., & Gan, W. S. DCASE 2021 task 3: spectrotemporally-aligned features for polyphonic sound event localization and detection. In: DCASE2021 (2021)
- Sun, X., Zhu, X., Hu, Y., Chen, Y., Qiu, W., Tang, Y., He, L., & Xu, M. Sound event localization and detection based on crnn using adaptive hybrid convolution and multi-scale feature extractor. In: DCASE2021 (2021)
- Sudarsanam, P., Politis, A., & Drossos, K. Assessment of self-attention on learned features for sound event localization and detection. In: DCASE2021 (2021)
- Huang, D. L., & Perez, R. F. Sseldnet: a fully end-to-end sample-level framework for sound event localization and detection. In DCASE2021 (2021)
برای دانلود پروژه نمونه طبقه بندی صدای محیطی در میکروکنترلرها با استفاده از شبکه های عصبی کانولوشن به همراه شبیه سازی، اینجا کلیک کنید.
پروژه مشابه دارید؟
برای ثبت سفارش در سیمیا می توانید از طریق اپلیکیشن سیمیا، یا فرم ثبت سفارش در سایت اقدام کرده و یا از طریق ایمیل، واتساپ، تلگرام و اینستاگرام اقدام نمایید.
اپلیکیشن سیمیا را از بازار و مایکت دانلود کنید.
سریع ترین راه پاسخگویی سیمیا، واتساپ و سروش می باشد. لینک واتساپ، اینستاگرام و تلگرام در پایین سایت وجود دارد.
09392265610
نشانی ایمیل سیمیا simiya_ht@yahoo.com می باشد.
از برقراری تماس برای هماهنگی پروژه خودداری کنید، حجم بالای سفارشات به ما اجازه نمی دهد تا از طریق تلفن پاسخگوی شما عزیزان باشیم، حتما درخواست خود را به صورت مکتوب و از طریق یکی از راه های ذکر شده فوق ارسال نمایید، درخواست خود را به طور کامل و با تمام فایل ها و توضیحات لازم ارسال نمایید تا مدت زمان بررسی آن به حداقل برسد. پس از تعیین کارشناس، در اسرع وقت به شما پاسخ می دهیم.